
Authors: Ahmed Radwan, Shaina Raza
An AI system that summarizes a customer-service call, supports learning from a medical consultation, or reviews a video interview must do more than recognize objects or transcribe speech. It must understand what was said, how it was said, what happened, and when it happened, and it must perform reliably across different people and real-world settings.
Consider a job applicant asked to record video answers through an online hiring platform. An AI system may be used to summarize the interview, score responses, or help decide whether the applicant moves to the next stage. But when that system operates as a black box, it is difficult to know whether it understood the candidate fairly, interpreted their tone and communication style correctly, or performed consistently across people of different ages, genders, and racial backgrounds. A system involved in decisions that affect people’s opportunities should not be trusted simply because it produces an answer.
Yet most evaluations of multimodal AI still focus on static images, short clips, or text transcripts. They rarely test whether models can jointly reason over natural audio and video in longer conversations, identify the moment an important event occurs, or reveal whether performance differs across demographic groups.
That is why we created Social Natural Interaction Corpus, Omnimodal v1 SONIC-O1: an open, human-verified benchmark for evaluating multimodal large language models on real-world audio-video understanding. It is designed to help researchers and practitioners measure where today’s AI systems succeed, where they fail, and what those failures could mean when models are applied in socially important settings.
SONIC-O1 is built to address this gap.
A benchmark grounded in real interactions
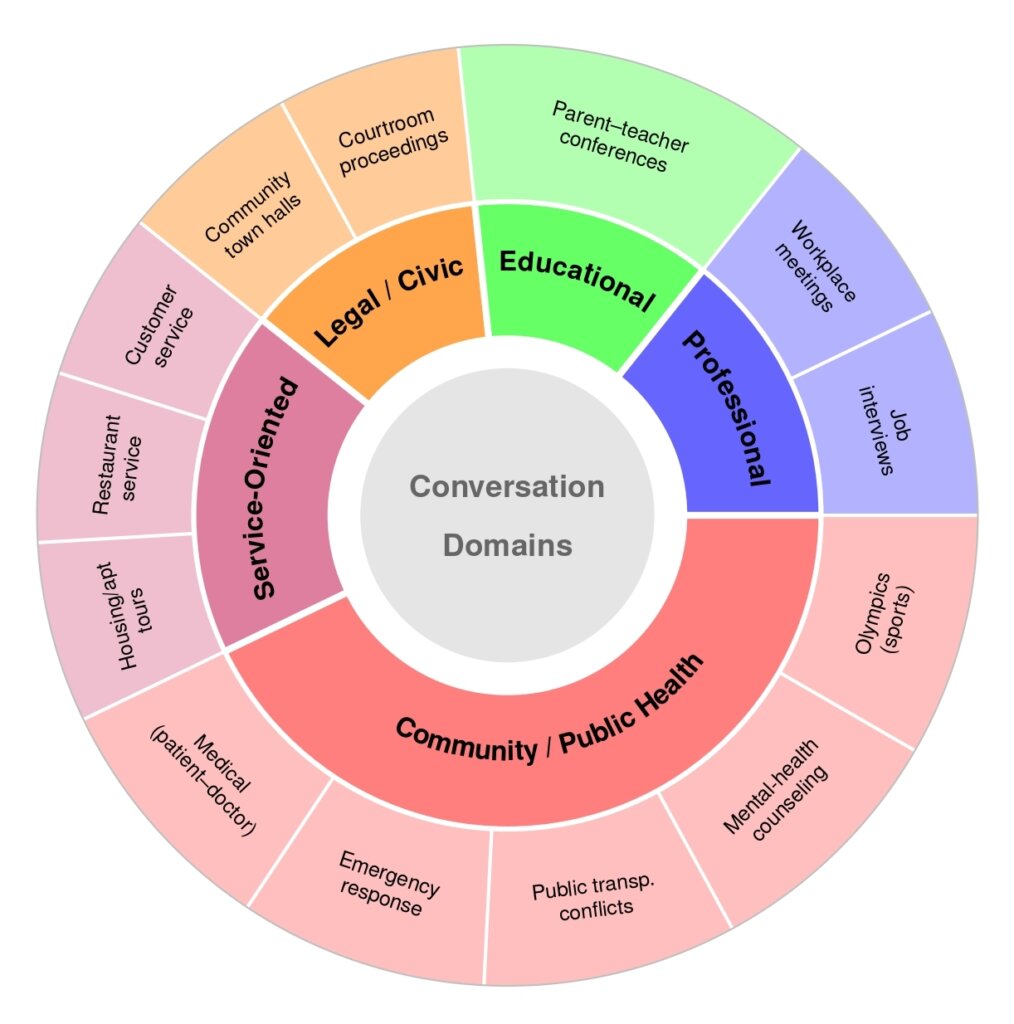
SONIC-O1 contains approximately 60 hours of real-world audio-video content drawn from 231 human-reviewed videos across 13 conversational topics and five broader domains:
- Professional interactions, including job interviews and workplace meetings
- Educational conversations, including parent-teacher conferences
- Legal and civic settings, including courtroom proceedings and community town halls
- Service-oriented interactions, including customer service, restaurant encounters, and housing tours
- Community and public-health settings, including patient-doctor consultations, emergency response, public-transit conflicts, mental-health counselling, and sports coverage
The videos range from short clips to conversations lasting up to an hour. This gives the benchmark a broader view of model capability than datasets focused only on brief, highly edited media. SONIC-O1 includes 4,958 human-verified annotations and associated metadata that supports group-wise analysis across observable demographic categories.
Three tasks, one central question: Does the model truly understand the interaction?
SONIC-O1 evaluates three connected capabilities.
1. Video summarization: The first task asks models to produce a coherent summary of a full audio-video interaction.
2. Evidence-grounded multiple-choice questions: The second task tests fine-grained understanding through multiple-choice questions based on short audio-video segments.
3. Temporal localization with reasoning: The third task asks models to identify when an event happens. For example, a model may need to determine when a particular goal is scored in a sports clip, when a speaker makes a key statement, or whether one event occurs before or after another. The model must predict the start and end time of the target event and explain the evidence supporting its answer.

For SONIC-O1, we selected openly licensed videos and reviewed them for quality, relevance, and clarity.
What we found: Audio-video understanding is still far from solved
We evaluated leading closed-source and open-source multimodal models across SONIC-O1’s three tasks: video summarization, evidence-grounded multiple-choice reasoning, and temporal localization.
The overall results show meaningful progress, but also clear limitations. Closed-source models performed best across the benchmark, particularly on open-ended summarization and temporal localization. The gap was smaller for multiple-choice questions, suggesting that current systems are relatively stronger when they can select from a fixed set of answers.
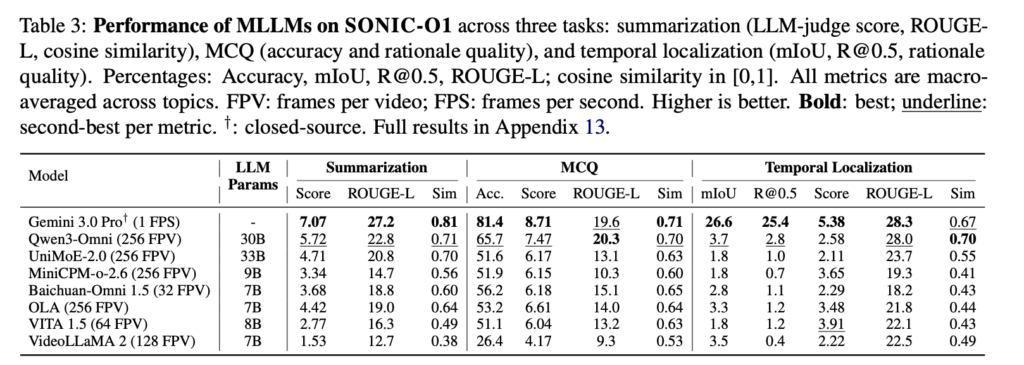
The most difficult task was temporal localization, which requires models to identify precisely when an event occurs in a video. Gemini 3.0 Pro achieved 25.4% R@0.5, compared with 2.8% for the strongest open-source model, Qwen3-Omni. This is a 22.6% gap. Models can often describe what happened or answer a question about a clip, but still struggle to reliably identify when the relevant evidence appears.
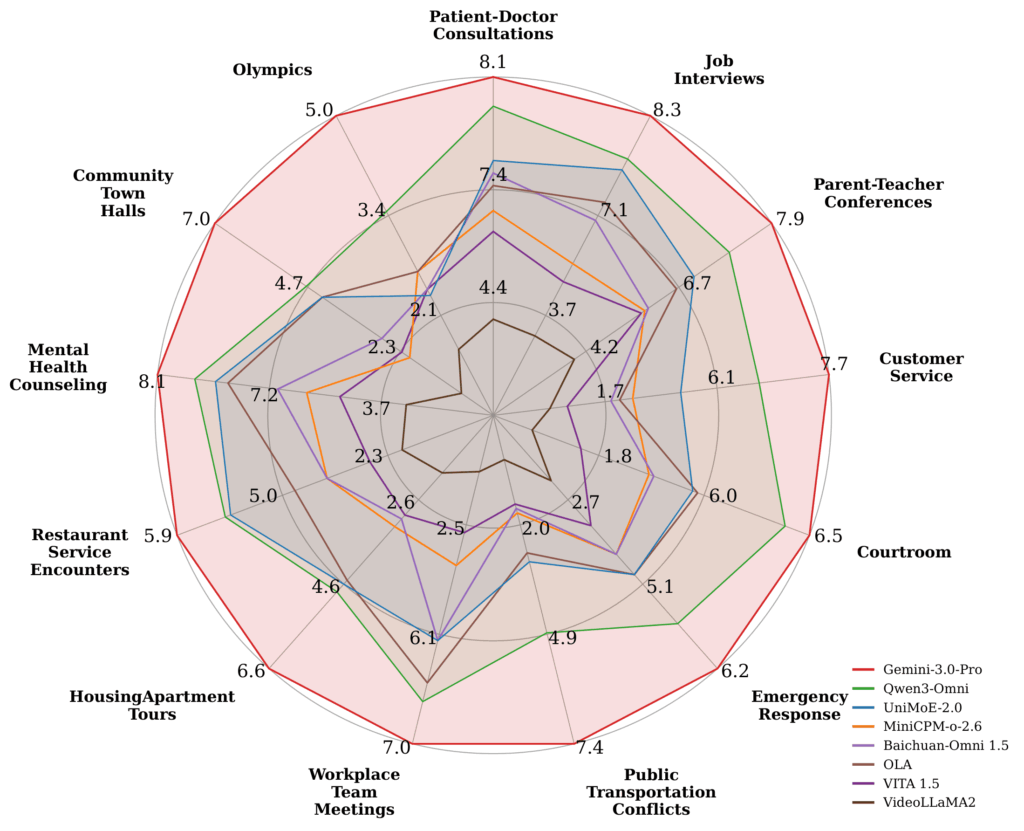
Performance also varied across real-world settings. The Figure below shows that no model performed equally well across all 13 conversational domains. High-stakes interactions such as emergency response and mental-health counselling remain especially demanding because they require models to connect spoken language, visual context, timing, and subtle social cues.
Group-wise analysis revealed the largest disparities in temporal localization, including a 21.4% gap for Gemini 3.0 Pro between Indigenous and Black participants, showing that overall averages can mask uneven reliability across demographic groups.
SONIC-O1 gives researchers and developers a shared framework to investigate these questions.






