
Auteurs : Ahmed Radwan, Shaina Raza
Un système d’IA qui résume un appel de service à la clientèle, soutient l’apprentissage d’une consultation médicale ou examine une entrevue vidéo doit faire plus que reconnaître des objets ou transcrire la parole. Il doit comprendre ce qui a été dit, comment cela a été dit, ce qui s’est passé, et quand c’est arrivé, et il doit fonctionner de façon fiable à travers différentes personnes et contextes réels.
Imaginez un candidat à qui on demande d’enregistrer des réponses vidéo via une plateforme d’embauche en ligne. Un système d’IA peut être utilisé pour résumer l’entrevue, évaluer les réponses ou aider à décider si le candidat passe à l’étape suivante. Mais lorsque ce système fonctionne comme une boîte noire, il est difficile de savoir s’il a bien compris le candidat, s’il a bien interprété son ton et son style de communication, ou s’il a performé de façon constante entre des personnes d’âges, de genres et de milieux raciaux différents. Un système impliqué dans les décisions qui affectent les opportunités des gens ne devrait pas être digne de confiance simplement parce qu’il produit une réponse.
Pourtant, la plupart des évaluations de l’IA multimodale se concentrent encore sur des images statiques, de courts extraits ou des transcriptions textuelles. Ils testent rarement si les modèles peuvent raisonner conjointement sur l’audio et la vidéo naturels dans des conversations plus longues, identifier le moment où un événement important survient, ou révéler si la performance diffère selon les groupes démographiques.
C’est pourquoi nous avons créé Social Natural Interaction Corpus, Omnimodal v1 SONIC-O1 : un benchmark ouvert et vérifié par l’humain pour évaluer les grands modèles de langage multimodaux sur la compréhension audio-vidéo du monde réel. Il est conçu pour aider les chercheurs et les praticiens à mesurer où les systèmes d’IA actuels réussissent, où ils échouent, et ce que ces échecs pourraient signifier lorsque des modèles sont appliqués dans des contextes socialement importants.
SONIC-O1 est conçu pour combler cette lacune.
Un repère fondé sur des interactions réelles
SONIC-O1 contient environ 60 heures de contenu audio-vidéo réel tiré de 231 vidéos évaluées par des humains sur 13 sujets de conversation et cinq domaines plus larges :
- Interactions professionnelles, y compris les entrevues d’embauche et les réunions en milieu de travail
- Conversations éducatives, y compris les rencontres parents-enseignants
- Des contextes juridiques et civiques, y compris les audiences judiciaires et les assemblées publiques communautaires
- Interactions axées sur le service, incluant le service à la clientèle, les rencontres au restaurant et les visites guidées de logements
- Milieux communautaires et de santé publique, incluant les consultations patient-médecin, l’intervention d’urgence, les conflits dans le transport en commun, le counseling en santé mentale et la couverture sportive
Les vidéos vont de courts extraits à des conversations pouvant durer jusqu’à une heure. Cela donne à la référence une vision plus large des capacités du modèle que les ensembles de données axés uniquement sur des médias courts et très édités. SONIC-O1 comprend 4 958 annotations vérifiées par l’homme et des métadonnées associées qui soutiennent une analyse par groupe à travers des catégories démographiques observables.
Trois tâches, une question centrale : le modèle comprend-il vraiment l’interaction?
SONIC-O1 évalue trois capacités connectées.
1. Résumé vidéo : La première tâche demande aux modèles de produire un résumé cohérent d’une interaction audio-vidéo complète.
2. Questions à choix multiples fondées sur des preuves : La deuxième tâche teste une compréhension fine à travers des questions à choix multiples basées sur de courts segments audio-vidéo.
3. Localisation temporelle avec raisonnement : La troisième tâche demande aux modèles d’identifier quand un événement se produit. Par exemple, un modèle peut devoir déterminer quand un but particulier est marqué dans un extrait sportif, quand un intervenant fait une déclaration clé, ou si un événement se produit avant ou après un autre. Le modèle doit prédire l’heure de début et de fin de l’événement cible et expliquer les preuves soutenant sa réponse.

Pour SONIC-O1, nous avons sélectionné des vidéos sous licence ouverte et les avons évaluées pour leur qualité, leur pertinence et leur clarté.
Ce que nous avons découvert : La compréhension audio-vidéo est encore loin d’être résolue
Nous avons évalué les principaux modèles multimodaux propriétaires et open source à travers les trois tâches de SONIC-O1 : résumé vidéo, raisonnement à choix multiples fondé sur des preuves et localisation temporelle.
Les résultats globaux montrent des progrès significatifs, mais aussi des limites claires. Les modèles à code source fermé ont obtenu de meilleurs résultats à travers le benchmark, particulièrement en résumé ouvert et localisation temporelle. L’écart était plus faible pour les questions à choix multiples, ce qui suggère que les systèmes actuels sont relativement plus forts lorsqu’ils peuvent choisir parmi un ensemble fixe de réponses.
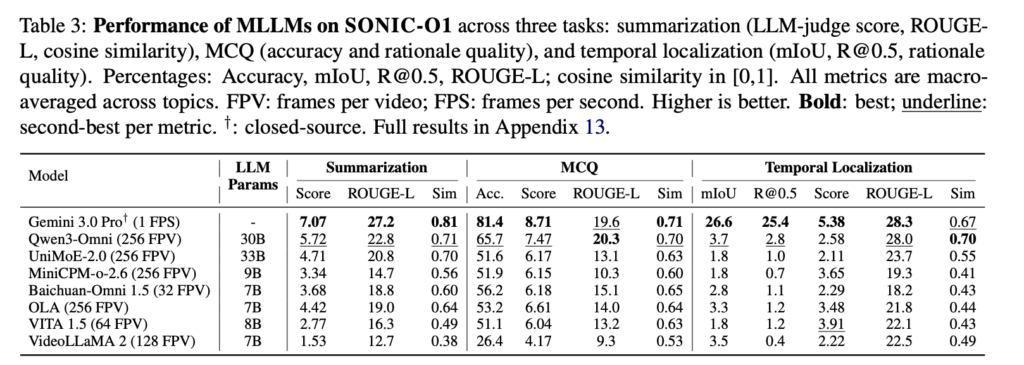
La tâche la plus difficile était la localisation temporelle, qui exige que les modèles identifient précisément quand un événement se produit dans une vidéo. Gemini 3.0 Pro a atteint 25,4% R@0,5, comparativement à 2,8% pour le modèle open source le plus puissant, Qwen3-Omni. C’est un écart de 22,6%. Les modèles peuvent souvent décrire ce qui s’est passé ou répondre à une question sur un extrait, mais ont encore du mal à identifier de façon fiable quand les preuves pertinentes apparaissent.
La performance variait aussi selon les environnements réels. La figure ci-dessous montre qu’aucun modèle n’a performé aussi bien dans les 13 domaines conversationnels. Les interactions à enjeux élevés comme l’intervention d’urgence et le counseling en santé mentale restent particulièrement exigeantes parce qu’elles nécessitent des modèles pour relier le langage parlé, le contexte visuel, le timing et des signaux sociaux subtils.
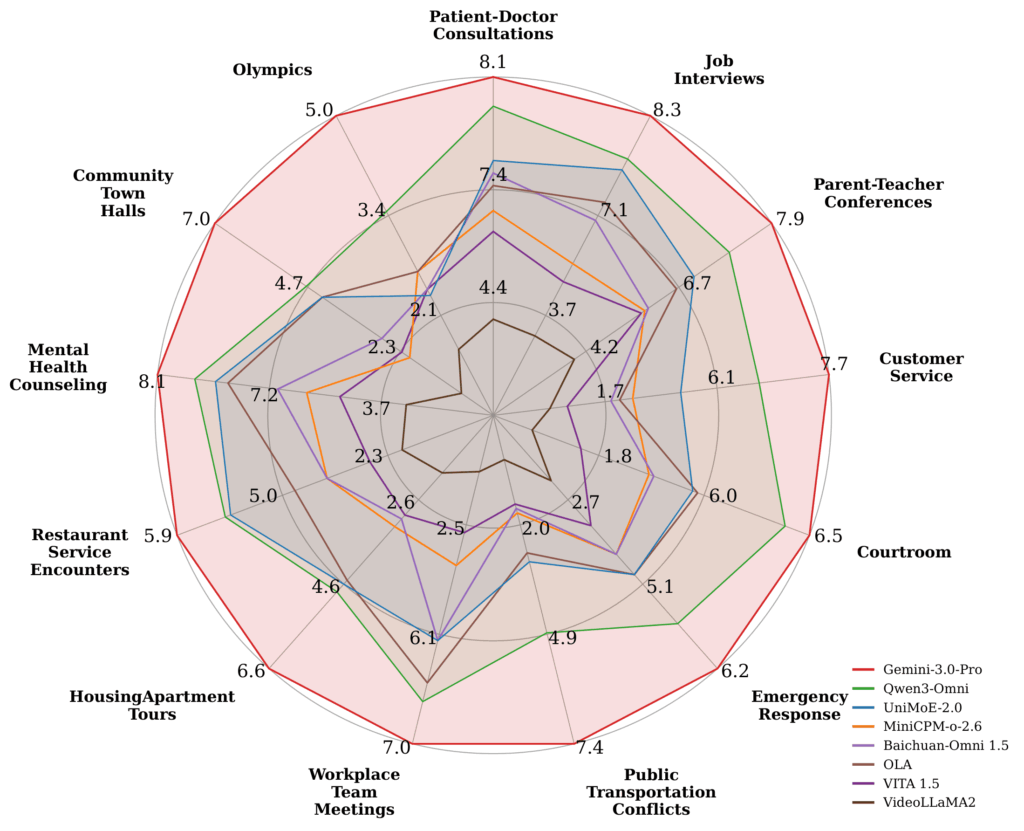
L’analyse par groupe a révélé les plus grandes disparités dans la localisation temporelle, incluant un écart de 21,4% pour Gemini 3.0 Pro entre les participants autochtones et noirs, montrant que les moyennes globales peuvent masquer une fiabilité inégale entre les groupes démographiques.
SONIC-O1 offre aux chercheurs et aux développeurs un cadre commun pour explorer ces questions.







