
Par David Emerson
Introduction
Avec l’émergence récente de grands modèles de langage (LLM) à haute performance et à usage général, tels que ChatGPT et LLaMA, on observe une expansion rapide tant de la recherche que de l’intérêt public pour les capacités et l’application de ces LM. Alors qu’une quantité croissante de ressources est concentrée sur l’avancement des frontières du traitement du langage naturel (NLP), et des LLM en particulier, il devient difficile de suivre ces changements. Dans cet article, nous proposons une discussion sur certaines tendances récentes des LLM et des techniques pour les appliquer aux tâches en aval, grâce à l’ingénierie des prompts. Nous discuterons également de nouvelles méthodes pour améliorer leurs performances au-delà du cadre traditionnel de l’ajustement fin du modèle complet. De telles approches incluent l’ajustement fin des instructions et l’ajustement fin efficace par paramètres. L’objectif est de mieux comprendre comment les LLM sont formés et comment ils peuvent être utilisés pour résoudre des problèmes concrets.
Les modèles de langage deviennent plus grands et s’entraînent plus longtemps
Au cours des dernières années, deux tendances importantes se sont développées en ce qui concerne les architectures LM et la formation, renforcées par de nombreuses avancées et des efforts d’ingénierie importants. Ces deux tendances sont présentes dans le diagramme d’échelle montré à la Figure 1. Bien que certains modèles dans la figure soient de type encodeur uniquement, comme BERT et RoBERTa, la majorité des LLM contemporains sont des modèles génératifs-encodeur-décodeur ou transformateurs uniquement à décodeur. Par conséquent, ces architectures seront le principal sujet de la discussion à venir.
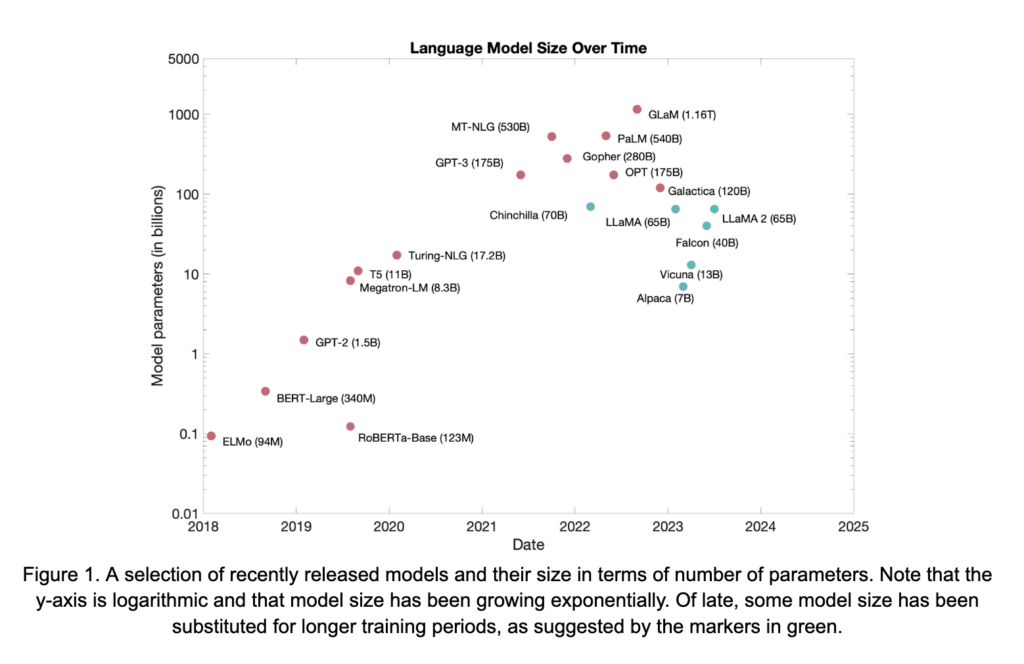
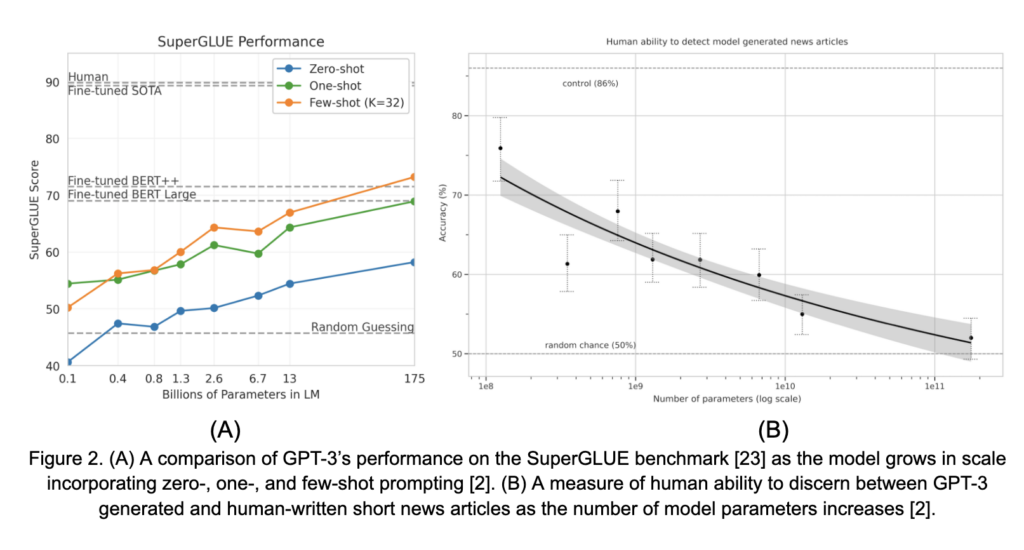
La première tendance visible à la Figure 1 est que les LLM ont connu une croissance rapide au fil du temps. La mise à l’échelle de ces modèles a été facilitée de plusieurs façons, notamment de meilleures techniques de pré-entraînement, des corpus pré-entraînement plus grands, ainsi que des avancées en matériel et en méthodes d’entraînement distribuées, entre autres. Cependant, cette augmentation de la taille du modèle n’est pas simplement pour des raisons d’échelle. Les capacités de ces modèles, en particulier leurs capacités de zéro et peu de tirs (discutées en détail ci-dessous), augmentent considérablement avec l’échelle. Cela a été souligné de façon poignante dans [2]. Deux résultats de ce travail sont présentés à la Figure 2. À la Figure 2A, la performance de GPT-3 sur le benchmark SuperGLUE, dans des configurations à zéro ou peu de plans, augmente en douceur avec la taille du modèle. De même, dans la Figure 2B, la capacité humaine à distinguer entre des articles courts générés par GPT-3 et ceux écrits par des humains diminue progressivement vers le hasard à mesure que le modèle grandit en taille. Ces observations, ainsi que d’autres, ont suscité un intérêt important pour l’échelle LM comme moyen d’acquérir des capacités générales en tâches en PNL.
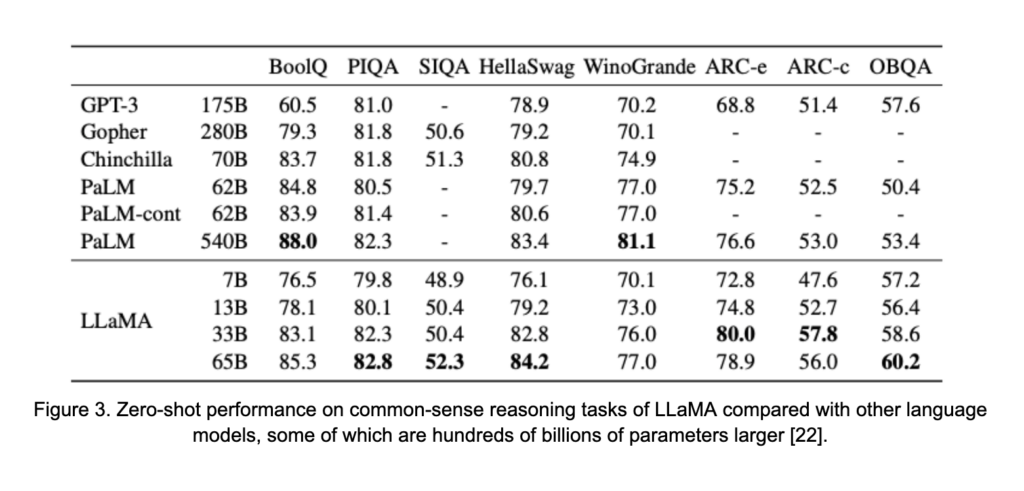
Le deuxième thème qui émerge dans les LLM est plus subtilement présent à la Figure 1. Sur le côté droit, mis en évidence en vert, se trouvent plusieurs modèles récemment sortis et performants. Bien que ces modèles restent assez grands, dans les dizaines de milliards de paramètres, ils ne suivent pas nécessairement la tendance d’échelle qui pourrait être déduite des modèles en rouge. Les modèles échangent une certaine taille en échange de plus grands ensembles de données pré-entraînement et de phases de pré-entraînement plus longues. Ce changement est motivé par l’étude de [8], qui a suggéré que, malgré les ressources déjà importantes utilisées pour entraîner de nombreux LLM, les modèles précédents sont sous-entraînés par rapport à leur taille. Cela a mené, par exemple, au cadre d’entraînement LLaMA [22], qui a vu 1,4 billion de jetons pendant l’entraînement. Ce total représente un bond important par rapport aux 300 milliards de jetons observés par l’OPT-175B [29], un modèle beaucoup plus grand, durant sa phase de pré-entraînement. Les résultats sont présentés à la Figure 3. Malgré sa taille plus petite, LLaMA surpasse les modèles avec jusqu’à 0,5 billion de paramètres.
Incitation : Motivation, avantages et construction
Formellement, le prompting est le processus consistant à utiliser des phrases ou des modèles soigneusement élaborés pour construire un texte d’entrée qui conditionne un gestionnaire de logiciel préentraîné à accomplir une tâche en aval. Nous avons déjà vu, dans les Figures 2A et B, que les LLM à demande sont capables d’effectuer des tâches avec un degré surprenant de précision sans nécessiter d’ajustements fins. Avant d’en discuter davantage, considérez le modèle d’invite suivant et la demande complétée associée pour la tâche BoolQ, tirée de [2].
![Figure montrant le modèle d’invite utilisé pour les tâches de compréhension de lecture accompagnée d’un exemple rempli. Le côté gauche affiche la structure abstraite du modèle : l’entrée commence par un titre temporaire et un passage, suivi du mot « question :' en violet et d’un « réponse :' en vert avec le jeton [X] indiquant où la réponse du modèle est attendue. Le côté droit montre un exemple concret : le passage dit : « La transmission de la rage – La transmission entre humains est extrêmement rare, bien qu’elle puisse se produire par transplantation d’organes ou par morsures. » La question affichée en violet est « une personne peut-elle transmettre la rage à une autre personne? » avec le champ de réponse vide, indiquant que c’est la cible de prédiction.](https://vectorinstitute.ai/wp-content/uploads/2023/10/Screenshot-2023-10-20-at-11.13.08-AM-1024x175.png)
À gauche se trouve un exemple de modèle de prompt. Chaque composant entre crochets inclinés est rempli d’informations provenant de la tâche que nous espérons accomplir. Le texte lavande est une structure créée pour présenter clairement le modèle avec les informations requises. Enfin, l’objectif est que le modèle génère du texte à la place du « X » de la marine avec la bonne réponse à la question. À droite se trouve un exemple du modèle rempli pour une question, avec du contexte, provenant de l’ensemble de données BoolQ.
Incitation à zéro ou peu de coups
La consigne ci-dessus est connue sous le nom de demande « zero-shot ». Il n’inclut aucun exemple « marqué », également appelé démonstrations ou tirs, dans l’entrée du LM. Peu de prompts fournissent des exemples identifiés dans le modèle de prompt, dans le but de fournir des conseils supplémentaires spécifiques à chaque tâche au LM. Des exemples de prompts one-shot et few-shot pour une tâche de classification par sentiment sont ci-dessous.

Il y a plusieurs avantages à inclure des démonstrations dans les consignes. La principale d’entre elles est que la performance des tâches en aval est souvent améliorée, comme le montre la Figure 2. L’écart entre les indications à zéro et à peu de plans s’élargit souvent avec l’échelle du modèle. De plus, l’inclusion d’exemples identifiés encourage fortement le modèle à répondre de manière à faciliter le mappage du texte généré sur une étiquette, ce qui est un défi courant avec les invitations. Considérez la tâche d’analyse de sentiment ci-dessus. L’espace d’étiquette pour la tâche est « positif » et « négatif ». Cependant, le modèle, laissé à lui-même, pourrait plutôt répondre par « agréable » ou « décevant », compliquant le processus de détermination programmatique de l’étiquette prédite. Inclure des exemples aide le modèle à réagir comme on s’y attend.
La façon dont les LM intègrent les démonstrations dans le processus prédictif est nuancée. Plusieurs études ont démontré que la qualité, la distribution et même l’ordre des démonstrations fournies ont un impact fort et parfois imprévisible sur la capacité d’un modèle à accomplir une tâche en aval [17,18,26]. À cette fin, certaines recherches ont envisagé des stratégies pour sélectionner des démonstrations optimales à inclure dans une invite afin de maximiser la performance des tâches en aval plutôt que la simple sélection et l’ordre aléatoires [1,15].
Bien que l’incitation à quelques coups soit très efficace, il y a plusieurs inconvénients à garder en tête. Premièrement, les démonstrations occupent un espace précieux dans la capacité d’entrée des LM (aussi appelée contexte). En général, les transformateurs peuvent consommer un nombre fixe de jetons pour conditionner le processus de génération. Par exemple, LLaMA a une longueur de contexte fixe de 2048 jetons. Bien que cela semble être beaucoup de jetons, injecter plusieurs démonstrations s’accumule rapidement, surtout pour une tâche comme le résumé de documents où chaque démonstration peut incorporer un gros morceau de texte. Cela limite le nombre d’exemples pouvant être inclus dans les suggestions. Plus important encore, les grands contextes entraînent des coûts de calcul élevés et ralentissent l’inférence. C’est parce que, par exemple, l’attention dans les transformateurs est un opération, où
est le nombre de jetons dans le contexte.
Un autre inconvénient est que les données étiquetées peuvent être privées. Dans [6], les attaques d’inférence par adhésion ont été conçues avec succès pour révéler des données étiquetées utilisées dans des prompts à peu de shots. Bien que ce travail ait aussi proposé une approche pour protéger ces données, l’inclusion de données sensibles dans les consignes demeure un risque. Enfin, plusieurs travaux ont démontré que, pour certaines tâches, l’incitation à peu de coups n’est pas suffisante pour obtenir une bonne performance d’un LM [12,25]. Cela a motivé une recherche importante sur la chaîne de pensée incitation, qui sera discutée en détail dans un prochain billet de blogue.
![Tableau 1 montrant les scores de validation F1 pour une tâche de reconnaissance d’entité nommée basée sur BART après un réglage complet du modèle sur quatre modèles d’invites différents. Le tableau comporte trois colonnes : Modèle positif, Modèle négatif (étiqueté « sic ») et score F1 de validation. Rangée 1 : Positif – « ⟨ texte⟩ ⟨candidat ⟩ est une entité [X] »; Négatif – « ⟨ texte⟩ ⟨candidat ⟩ n’est pas une entité nommée »; Val. F1 : 95,27. Ligne 2 : Positif – « ⟨texte ⟩ Le type d’entité de ⟨ candidat ⟩ est [X] »; Négatif – « ⟨texte ⟩ Le type d’entité du ⟨ candidat ⟩ n’est aucune entité »; Val. F1 : 95,15. Ligne 3 : Positif – « ⟨text⟩ ⟨candidat⟩ appartient à la catégorie [X] »; Négatif – « ⟨ texte ⟩ ⟨candidat ⟩ n’appartient à aucune catégorie »; Val. F1 : 88,42. Ligne 4 : Positif – « ⟨candidat⟩ ⟨texte ⟩ doit être étiqueté comme [X] »; Négatif – « ⟨⟩ ⟨candidat texte⟩ doit être étiqueté comme aucune entité »; Val. F1 : 76,80. Le jeton [X] apparaît mis en évidence dans les modèles positifs, indiquant la cible de prédiction du modèle. Les deux premiers modèles obtiennent les scores les plus élevés, tous deux supérieurs à 95.](https://vectorinstitute.ai/wp-content/uploads/2023/10/Fig-6-1024x238.png)
La façon dont vous posez la question est importante
Pour la plupart des tâches en aval, l’objectif d’une invite est de maximiser la capacité des LM à effectuer cette tâche avec peu ou pas besoin de données indiquées. Cependant, même les LM les plus performants sont sensibles à la structure du prompt fourni. La façon dont vous demandez au modèle d’accomplir la tâche cible est importante, et parfois c’est même le facteur déterminant qui assure l’achèvement complet de la tâche. Considérons les exemples détaillés dans le tableau 1 de [4]. Chaque ligne du tableau correspond à un modèle potentiel pour une tâche de reconnaissance d’entité nommée. Il y a une grande différence de performance entre un modèle utilisant le meilleur prompt (rangée du haut) et le pire (rangée du bas). Cette différence est encore plus marquée lorsqu’on considère que le modèle est en fait affiné pour cette tâche à l’aide de ces structures d’invites. La sensibilité des LM à la structure des prompts est bien documentée et implique qu’une conception réfléchie des prompts peut avoir un impact important sur la performance du modèle.
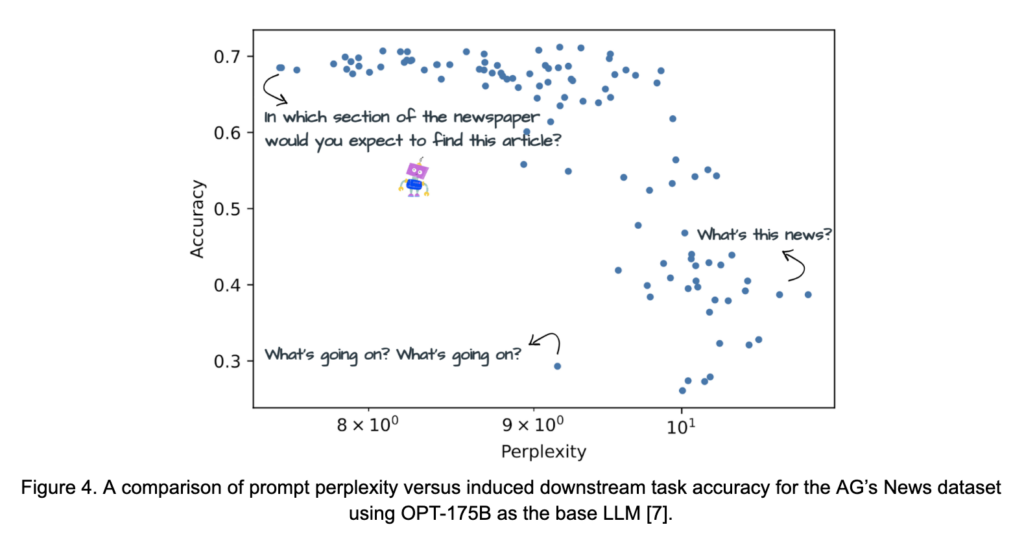
Dans cette optique, plusieurs études ont examiné la question : « qu’est-ce qui fait qu’une consigne est une bonne consigne? » La question est complexe, car certains types de prompts conviennent mieux à certains types de modèles. Par exemple, les auteurs de l’OPT ont observé que le modèle ne répondait pas bien aux « instructions déclaratives ou aux interrogatifs directs [29] ». Ce n’est pas nécessairement le cas pour les modèles à réglage précis de l’instruction, discutés ci-dessous, comme Vicuna [3]. Néanmoins, plusieurs études ont mis en lumière certains principes à garder en tête lors de la création de prompts. Dans [7], la relation entre l’efficacité d’un prompt et sa perplexité – une mesure proximale de la fluidité et de la simplicité d’un prompt du point de vue des LM – est étudiée. Cette relation est affichée pour les consignes destinées à classer les articles de presse en catégories dans la Figure 4. Le travail suggère empiriquement que les consignes simples, fluides et spécifiques à une tâche fonctionnent le mieux. Un autre ensemble d’études dans [19] a compilé un ensemble de suggestions de conception de prompts basées sur des expérimentations avec la famille GPT de LM. Celles-ci incluent :
- Utiliser des schémas de bas niveau plutôt que des concepts sophistiqués qui nécessitent une compréhension préalable
- Décomposer des tâches complexes en plusieurs tâches plus simples lorsque c’est possible
- Fournir les sorties et contraintes attendues et transformer les énoncés niés en énoncés d’assertion
Bien que ces recommandations aident à cibler l’exploration et la conception des prompts optimaux, il est important de reconnaître qu’il est souvent nécessaire d’expérimenter la construction des prompts pour obtenir une performance optimale d’un LM sur une tâche donnée.
Optimisation par prompt discret
Parce que la conception manuelle des invites peut être difficile et aussi cruciale pour la réussite d’une tâche en aval, une quantité importante de recherches a visé à améliorer le processus de recherche grâce à diverses procédures d’optimisation. Les approches les plus simples visent à générer un ensemble diversifié de prompts sur lesquels la performance peut être évaluée. Parmi les exemples, on retrouve le prompt mining [10], où la formulation et le texte courant sont extraits de grands corpus textuels pour construire des prompts variés, et la paraphrase des prompts [7,10,28], dans laquelle une grande variété de prompts est créée à partir de prompts « seed » via des traductions aller-retour, le remplacement de thésaurus ou des modèles de paraphrases. Chacune de ces méthodes vise à élargir les incitations conçues par l’humain afin d’évaluer un plus grand bassin de candidats. Une variante sophistiquée de ces approches est GrIPS [20], qui combine ces approches, ainsi que plusieurs schémas d’édition de texte, pour rechercher de manière itérative des conceptions optimales de prompts.
Une approche d’optimisation intéressante, connue sous le nom d’AutoPrompt, est proposée dans [21]. L’approche recherche un ensemble de jetons « déclencheurs » de la forme
![Une expression mathématique définissant la structure d’un modèle d’invite pour les tâches du modèle de langage masqué. La formule se lit comme suit : x-subscripte-invite égale ⟨texte⟩ [t₁] ... [tn] [MASQUE], suivi d’un point. Dans la formule, x-subscript-prompt est rendu en gras pour indiquer l’entrée complète de l’invite; ⟨ texte ⟩ représente le texte d’entrée temporaire; [t₁] à [tn] représentent une séquence de n jetons d’invite apprenables; et [MASK] est la position du jeton masqué où le modèle de langage est censé générer une prédiction. Tous les éléments de place et de jetons sont rendus en bleu.](https://lh3.googleusercontent.com/P0qoz6LYh9DgKwTD4p61Tv90xYDXZA5VNeTbw9avd7GeEU8w8ygI4ZU5huNQmy2DiQRERU-oc1dOEUwOY9te-OgrAIuDUefSrAauQktLbNSNfllqvD-QYY5XWwKIQaObWuRsAbB1ncvOxdIuhE-pWbA)
Soit représentent le vocabulaire du LM considéré. Pour une étiquette
et la portion associée du vocabulaire, les prompts sont notés comme
![Equation 3.1 defining the probability of a label given a prompt in a masked language model setting. The equation reads: P of y given x-subscript-prompt equals the sum over all w belonging to V-subscript-y of P of [MASK] equals w given x-subscript-prompt. In this expression, y is the predicted label, x-subscript-prompt is the structured prompt input, V-subscript-y is the vocabulary of words associated with label y, w is a candidate word from that vocabulary and [MASK] is the masked token position the model is asked to fill. The equation defines the label probability as the aggregated probability mass the model assigns to all vocabulary terms associated with that label at the mask position.](https://lh4.googleusercontent.com/y5qQNipO2_sAjdITH2piAlCFufxPH27fXxlWxq5iFgrqo46OQPXQG-rA9v-pSFG__XPIMjoiJoswsDnHNwmLvHLda4rKg4HBpBfPuVtDitT5rG_jNX4N_uNxMGvbSECFqS1ASOKNeljtVSv95xOp4Ck)
À chaque itération, un jeton, , avec l’immersion
est sélectionné pour modification. Nous cherchons
, avec l’immersion
, avec le plus grand potentiel d’augmentation de la probabilité d’étiquette, telle qu’exprimée dans l’équation (3.1),
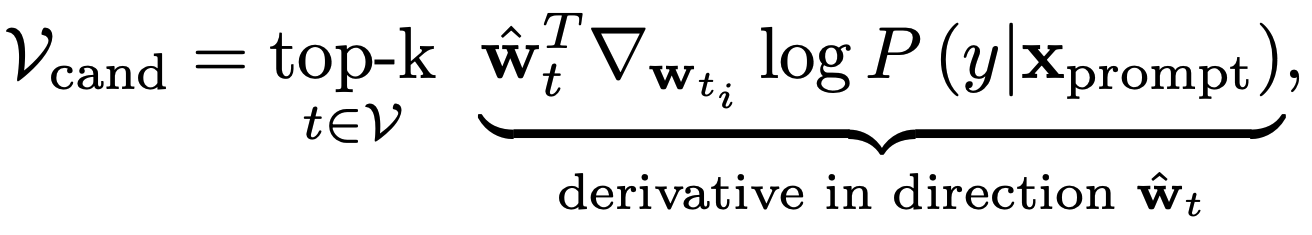
où est le nombre de jetons de remplacement candidats à considérer. Modification de la
-th jeton de prompt avec
pour former
, on sélectionne le
qui maximise les probabilités d’étiquette sur un lot d’entraînement dessiné indépendamment
comme
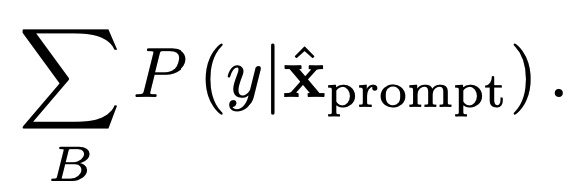
Cette approche peut être très productive pour augmenter l’efficacité rapide, comme on le voit dans le tableau 2. La précision induite par les indications manuelles des modèles BERT et RoBERTa pour le sentiment SST-2 est améliorée respectivement de 19,1% et 6,2%. Bien que ces améliorations soient assez importantes, il y a quelques inconvénients à cette approche. La première est que la méthode nécessite le calcul d’un gradient par rapport aux plongements du vocabulaire du modèle. Bien qu’aucun paramètre ne soit mis à jour dans ce processus, le calcul du gradient pour les LLM, même pour un petit sous-ensemble des paramètres, peut être très gourmand en ressources. De plus, les invites résultant de cette approche d’optimisation basée sur les jetons sont souvent difficiles à lire et ont tendance à ne pas ressembler à des prompts qu’un humain pourrait créer. Cela est mis en évidence dans le tableau 3. Certaines recherches actuelles visent à aborder ce problème, qui, en général, affecte de nombreuses autres approches d’optimisation discrète des prompts comme RLPrompt [5]. Cependant, cela reste un domaine d’enquête actif.
![Deux tables présentées ensemble. Le tableau 2 montre la performance sur la tâche de classification du sentiment SST-2 en comparant les invites manuelles et générées par AutoPrompt sur quatre configurations de modèles. Le tableau comporte trois colonnes : Modèle, Compte de développement et Compte de test Ligne 1 : BERT (invite manuelle) – 63.2 / 63.2. Rangée 2 : BERT (AutoPrompt) – 80,9 / 82,3. Rangée 3 : RoBERTa (invite manuelle) – 85,3 / 85,2. Rangée 4 : RoBERTa (AutoPrompt) – 91,2 / 91,4. L’Autoprompt surpasse constamment les invitations manuelles pour les deux modèles, RoBERTa (AutoPrompt) obtenant les meilleurs scores dans l’ensemble. Le tableau 3 présente trois tâches avec leurs modèles d’invites associés et les prompts optimaux découverts par AutoPrompt. Les colonnes sont : Tâche, Modèle et Invite trouvés par AutoPrompt. Rangée 1 : Analyse du sentiment – modèle « ⟨texte ⟩ [t₁] ... [tn] [MASK] » – prompt « implacablement sombre et désespéré Écrivain universitaires où l’étranger apparaîtra [X] ». Rangée 2 : NLI – modèle de « ⟨ prémisse ⟩ [MASQUE] [t₁] ... [tn] (hypothèse) » – invite « Deux chiens se battent et s’embrassent [X] lieu de travail concret Il n’y a pas de lutte et de câlins de chiens ». Rangée 3 : Recherche de faits – modèle « ⟨sujet ⟩ [t₁] ... [tn] [MASK] » – prompt « Hall Overton fireplacemade antique son alto [X] ». Dans la colonne AutoPrompt, les jetons d’invite optimisés sont mis en évidence en lavande. La légende note que, bien que ces prompts fonctionnent bien selon leurs métriques respectives, ils sont difficiles à interpréter ou à comprendre sémantiquement.](https://vectorinstitute.ai/wp-content/uploads/2023/10/Screenshot-2023-10-20-at-11.19.46-AM-1024x580.png)
IFT et PEFT
L’incitation présente plusieurs avantages importants. Grâce aux incitations, les LLM démontrent une capacité remarquable à accomplir des tâches pour lesquelles ils n’ont jamais été formés. De plus, le multi-tâche par lots est facilement réalisé grâce à des incitations. C’est-à-dire que le même LLM peut être utilisé pour de nombreuses tâches différentes, même au sein d’un même lot, simplement en modifiant l’invite. De plus, l’interaction et l’inférence des modèles sont obtenues uniquement par le langage naturel, ce qui réduit les barrières à l’utilisation des modèles. D’un autre côté, nous savons que la performance des tâches reste assez sensible à la conception des prompts. De plus, la recherche d’incitations optimales est difficile et souvent fastidieuse. Enfin, et peut-être le plus important, pour de nombreuses tâches, un grand écart subsiste entre la performance des LLM à demande et des modèles spécifiques à une tâche entraînés pour effectuer une seule tâche avec une haute fidélité. Ces inconvénients ont motivé d’autres approches visant à améliorer la capacité des LLM à accomplir des tâches spécifiques en aval, tout en tentant de préserver autant que possible les avantages de l’approche par incitation.
Réglage fin des instructions
L’observation selon laquelle l’OPT ne répond pas bien aux « instructions déclaratives ou interrogatives à bout portant », brièvement évoquée plus haut, est à la fois une affirmation vraie à propos du LLM et un fait qui rend plus difficile d’inciter le modèle à effectuer des tâches en aval. Des instructions directes et des questions directes sont souvent une façon naturelle de commencer à interagir avec un gestionnaire de gestion génératif. L’ajustement fin des instructions (IFT) vise à améliorer la performance des indications tout en rendant le processus plus intuitif. L’idée de base est de fournir à un LM cible des exemples supplémentaires, au-delà de ceux vus lors de la pré-entraînement, avec une structure spéciale. Pour l’IFT, cette structure spéciale prend la forme d’invites d’instruction jumelées à une réponse générée souhaitée à travers une grande variété de tâches de PLN. L’échelle et la qualité de ces ensembles de données sont importantes pour le succès du processus IFT. L’une de ces collections de données est le jeu de données Natural Instruction V2 introduit par [24]. Cet ensemble de données comprend plus de 1600 tâches différentes, issues de 76 catégories de tâches différentes, chacune jumelée à une consigne basée sur des instructions. Une illustration des différentes tâches et de leur représentation relative dans l’ensemble de données est présentée à la figure 5.

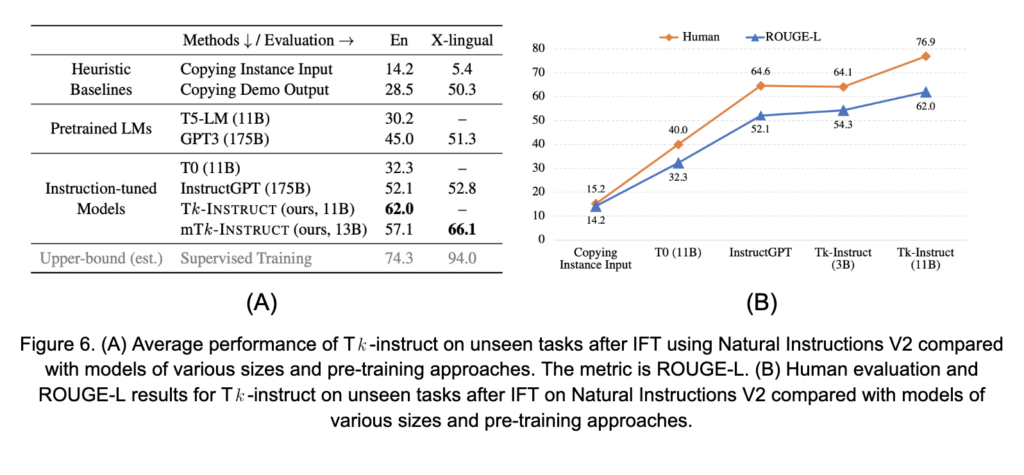
Pour l’IFT, le LM cible est encore affiné (aussi appelé méta-ajustement) à partir de texte tiré de l’ensemble de données IFT. L’inconvénient de cette approche est qu’elle nécessite des ressources computationnelles équivalentes à l’ajustement fin complet du modèle, bien que pour une période beaucoup plus courte que les cycles de pré-entraînement de la plupart des LLM. D’un autre côté, il a été démontré que cette approche améliore la capacité d’un LM à incorporer des invites et à effectuer les tâches en aval selon les instructions. Voyez, par exemple, les résultats de [24] présentés dans les Figures 6A et B. L’IFT conserve bon nombre des avantages de l’incitation tout en visant à améliorer l’efficacité de l’incitation pour les modèles cibles. Les principaux inconvénients sont que l’IFT reste essentiellement un réglage fin, nécessite des critères d’arrêt rigoureux pour éviter de perdre les capacités générales du modèle (oublis catastrophiques), et ne comble pas nécessairement l’écart « à la fine pointe » grâce à l’ajustement fin spécifique à la tâche.
Réglage fin efficace par les paramètres
L’ajustement fin complet des LLM devient souvent complètement irréalisable en raison des ressources informatiques massives nécessaires pour effectuer la formation, même pour de courtes périodes [27]. De plus, même avec les ressources nécessaires pour produire une version spécifique d’un LLM, il est probable qu’un modèle distinct doive être affiné pour chaque tâche distincte, nécessitant la duplication de l’infrastructure de stockage, de calcul et d’hébergement pour réellement utiliser ces modèles. Par conséquent, des approches alternatives pour combler l’écart mentionné plus haut dans la performance des LLM incités ont été envisagées.
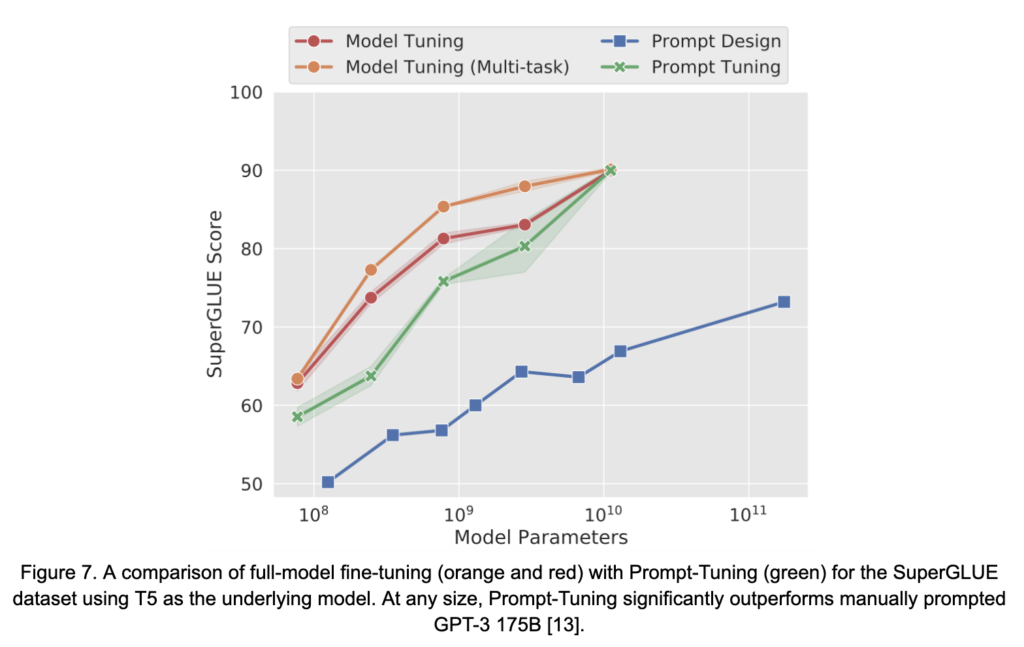
Une extension naturelle de l’optimisation par prompts discrets est la relaxation de l’espace de recherche des jetons discrets vers l’espace continu des embeddings de jetons par manipulation ou augmentation de la couche d’embedding des LM. Ces méthodes sont connues sous le nom de techniques d’optimisation continue des prompts et incluent des méthodes telles que le Prompt-Tuning [13], le Prefix-Tuning [14], et le P-Tuning [16], entre autres. Ces méthodes constituent une sous-catégorie de l’ajustement fin à efficacité paramétrique (PEFT). Les méthodes PEFT entraînent une petite fraction des paramètres globaux du modèle tout en visant à récupérer la précision obtenue grâce à l’ajustement fin complet du modèle. Les approches d’optimisation continue des prompts se concentrent sur la modification ou l’augmentation des paramètres du modèle d’une manière qui coïncide ou imite les indications d’injection en langage naturel. Grâce à cette technique, il a été démontré que ces approches rivalisent avec la performance de l’ajustement fin complet du modèle à travers plusieurs tâches de PLN, surtout à mesure que la taille du LM sous-jacent augmente, voir la Figure 7 de [13]. Les méthodes réalisent un multi-lot en s’assurant que les poids appropriés, spécifiques à chaque tâche et « associés à l’invite » accompagnent chaque exemple du lot lors de l’inférence. Cependant, l’interprétabilité des « consignes » apprises demeure un enjeu et une question ouverte [11].
Bien que les approches d’optimisation continue par prompt présentent de nombreux avantages, l’approche actuelle de pointe de la PEFT est l’adaptation à bas rang (LoRA) [9]. LoRA généralise l’adaptation de LM au-delà de l’incitation, mais se concentre toujours sur la modification du mécanisme d’attention du transformateur, comme c’est le cas dans le P-Tuning, par exemple. L’idée repose sur des observations empiriques selon lesquelles les poids des LLM sont de bas « rang intrinsèque ». C’est-à-dire que, bien que les tenseurs des LM soient de haute dimension, l’information qu’ils contiennent tend en fait à être bien approximée dans une dimension beaucoup plus basse. Cela se manifeste, par exemple, par une chute brutale des valeurs singulières associées à une décomposition singulière des poids du modèle.
Considérons une matrice de poids . L’hypothèse sous-jacente de LoRA est que, si
est de faible « rang intrinsèque », alors les ajustements finis des mises à jour pourraient aussi l’être. Pendant l’entraînement, LoRA fige les poids originaux,
et contraint les mises à jour aux matrices de bas rang
de la forme
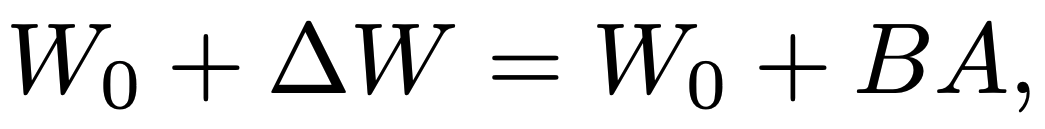
où et
et
est un petit entier. Si les mises à jour d’entraînement sont de rang inférieur, les poids dans
et
Cela devrait s’approcher approximativement de la vraie mise à jour. Cela est illustré à la figure 8.
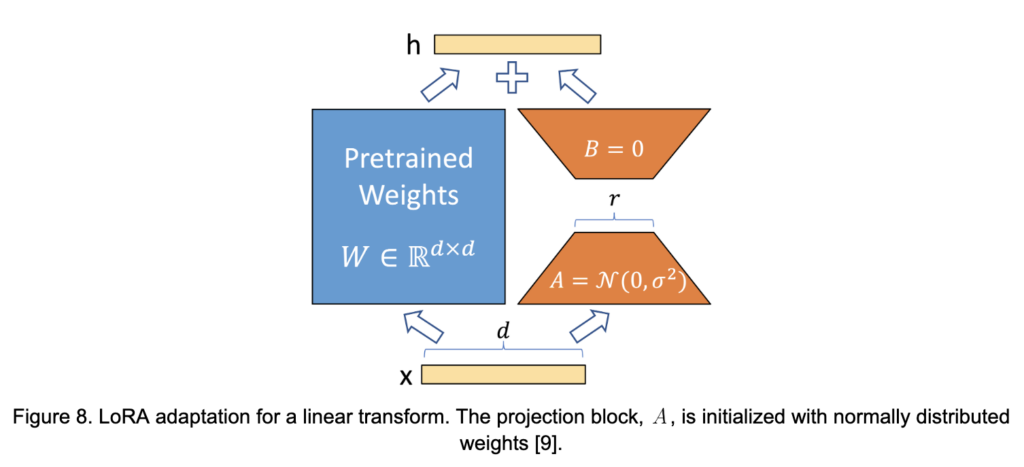
Il y a quatre matrices consécutives dans l’attention à plusieurs têtes ,
,
,
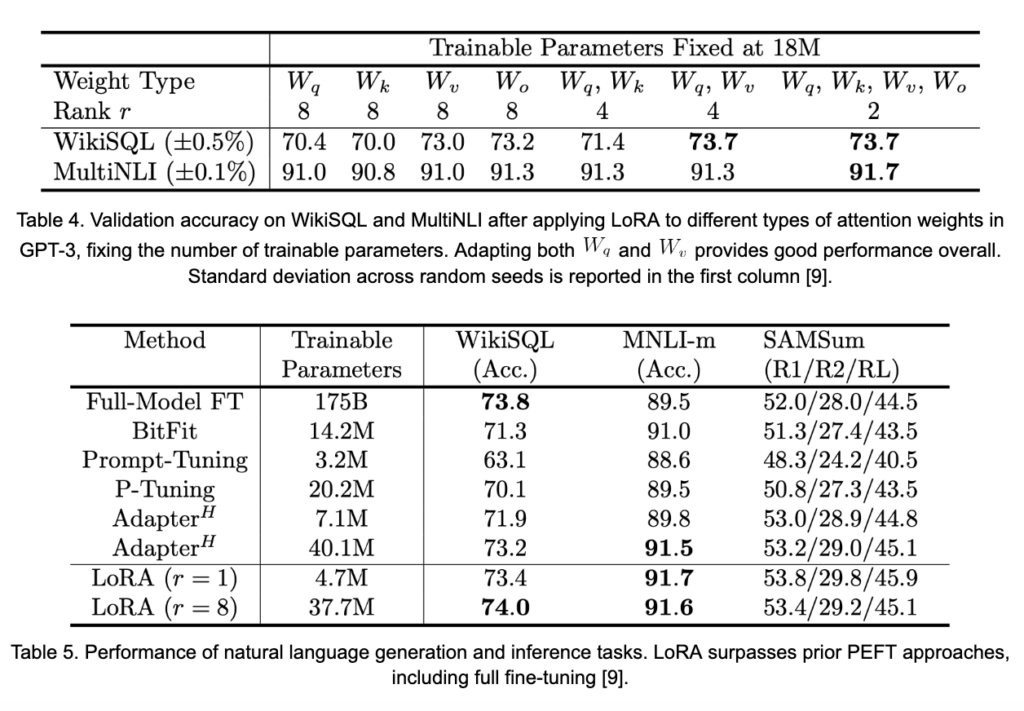
. Une question importante est : « quelles matrices devraient être adaptées pendant la formation? » Les résultats présentés dans le tableau 4 suggèrent qu’adapter au moins les deux
et
offre un gain notable de performance. Il est également important de noter que la magnitude de
peut être très petit, tout en générant de bonnes performances. Le plus petit
c’est-à-dire que moins de poids sont entraînés. Adaptation des matrices d’attention de
et
dans chaque couche de GPT-3 avec des valeurs pour
de
et
, LoRA est capable de capturer et de surpasser l’ajustement fin complet du modèle, comme on le voit dans le tableau 5.
Effectuer du batching multitâche avec LoRA est un peu plus compliqué comparé à des méthodes comme le Prompt-Tuning. Parce que LoRA reparamétrise essentiellement les composantes complètes du modèle à travers les matrices et
, les entrées associées à différentes tâches doivent être acheminées à travers différentes matrices LoRA afin de produire les sorties spécifiques à chaque tâche. Une telle approche est possible, mais nécessite un niveau élevé d’orchestration de l’infrastructure. Cependant, traiter des tâches séparées en lots homogènes consiste simplement à appliquer les bons poids LoRA, ce qui reste assez flexible. L’utilisation de LoRA pour les tâches en aval s’éloigne aussi de l’idée d’interagir avec les LM par le langage naturel, ce qui augmente le niveau d’expertise nécessaire pour réaliser les tâches en aval. Cependant, les avantages de performance de la LoRA en ont fait une approche extrêmement populaire pour obtenir une grande précision efficace pour une variété de tâches personnalisées grâce aux LLM.
Conclusion
Dans cet article, nous avons couvert une grande partie des recherches actuelles et émergentes sur les LLM. Ces modèles continuent de croître en taille, s’entraînent sur des ensembles de données de plus en plus volumineux et voient des billions de jetons durant leur phase de pré-entraînement. Les incitations et la conception des prompts continuent d’évoluer à mesure que notre compréhension des meilleures pratiques pour interagir avec les LLM par le langage naturel devient plus claire et que les capacités des LLM sont explorées. Nous avons discuté de méthodes de pointe pour générer automatiquement des prompts optimaux, tant dans le contexte du langage naturel que dans les espaces de dimensions supérieures des LLM eux-mêmes. Enfin, nous avons envisagé deux approches récentes pour accomplir des tâches spécifiques en aval avec une plus grande fidélité. La première, l’IFT, vise à améliorer la capacité des LLM à effectuer des tâches par incitation directe. La seconde, LoRA, est une technique extrêmement efficace pour affiner une petite fraction des poids totaux d’un LLM afin d’exécuter une tâche en aval avec une précision similaire à l’ajustement complet du modèle, réduisant ainsi les ressources nécessaires pour obtenir des performances à la fine pointe de la technologie pour une variété de tâches.
Références
[1] S. Agrawal, C. Zhou, M. Lewis, L. Zettlemoyer et M. Ghazvininejad. Sélection d’exemples contextuels pour la traduction automatique. Dans les résultats de l’Association for Computational Linguistics : ACL 2023, pages 8857–8873, Toronto, Canada, juillet 2023. Association pour la linguistique computationnelle.
[2] T. Brown, B. Mann, N. Ryder, M. Subbiah, J.D. Kaplan, P. Dhariwal, A. Neelakantan, et al. Les modèles de langage sont des apprenants peu puissants. Dans Advances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020.
[3] W.-L. Chiang, Z. Li, Z. Lin, Y. Sheng, Z. Wu, H. Zhang, L. Zheng, S. Zhuang, Y. Zhuang, J. E. Gonzalez, et al. Vicuna : Un chatbot open source impressionnant GPT-4 avec 90%* de qualité ChatGPT, mars 2023.
[4] L. Cui, Y. Wu, J. Liu, S. Yang et Y. Zhang. Reconnaissance d’entités nommées basée sur des modèles à l’aide de BART. Dans les résultats de l’Association for Computational Linguistics : ACL-IJCNLP 2021, pages 1835–1845, en ligne, août 2021. Association pour la linguistique computationnelle.
[5] M. Deng, J. Wang, C.-P. Hsieh, Y. Wang, H. Guo, T. Shu, M. Song, E.P. Xing et Z. Hu. RLPrompt : Optimiser les prompts textuels discrets avec l’apprentissage par renforcement. Dans la conférence sur les méthodes empiriques dans le traitement du langage naturel, 2022.
[6] H. Duan, A. Dziedzic, N. Papernot et F. Boenisch. Volées de perroquets stochastiques : apprentissage différentiel privé par incitations pour de grands modèles de langage. https://arxiv.org/abs/2305.15594, mai 2023.
[7] H. Gonen, S. Iyer, T. Blevins, N. Smith et L. Zettlemoyer. Démystifier les invites dans les modèles de langage par estimation de la perplexité. https://arxiv.org/abs/2212.04037, 12 2022.
[8] J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L.A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, J.W. Rae, O. Vinyals et L. Sifre. Entraînement de grands modèles de langage optimaux en calcul. Dans S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, et A. Oh, éditeurs, Advances in Neural Information Processing Systems, volume 35, pages 30016–30030. Curran Associates, Inc., 2022.
[9] E. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, L. Wang et W. Chen. Lora : Adaptation à bas rang de grands modèles de langage, 2021.
[10] Z. Jiang, F.F. Xuand J. Araki et G. Neubig. Comment pouvons-nous savoir ce que savent les modèles de langage? Transactions de l’Association for Computational Linguistics, 8:423–438, 2020.
[11] D. Khashabi, X. Lyu, S. Min, L. Qin, K. Richardson, S. Welleck, H. Hajishirzi, T. Khot, A. Sabharwal, S. Singh et Y. Choi. Égarement prompt : Le cas curieux de l’interprétation discrétisée des incitations continues. Dans les actes de la conférence 2022 du chapitre nord-américain de l’Association for Computational Linguistics : Human Language Technologies, pages 3631–3643, Seattle, États-Unis, juillet 2022. Association pour la linguistique computationnelle.
[12] T. Kojima, S.S. Gu, M. Reid, Y. Matsuo et Y. Iwasawa. Les grands modèles de langage sont des raisonnements à zéro coup. arXiv préprint arXiv :2205.11916, 2022.
[13] B. Lester, R. Al-Rfou, et N. Constant. La puissance de l’échelle pour un réglage prompt efficace en paramètres. Dans les actes de la conférence 2021 sur les méthodes empiriques en traitement du langage naturel, pages 3045–3059, en ligne et Punta Cana, République dominicaine, novembre 2021. Association pour la linguistique computationnelle.
[14] Xiang Lisa Li et Percy Liang. Préfix-tuning : Optimisation des prompts continus pour la génération. Actes de la 59e réunion annuelle de l’Association for Computational Linguistics et de la 11e Conférence internationale conjointe sur le traitement du langage naturel (Volume 1 : Long Papers), abs/2101.00190, 2021.
[15] J. Liu, D. Shen, Y. Zhang, B. Dolan, L. Carin et W. Chen. Qu’est-ce qui fait de bons exemples contextuels pour GPT-3? Dans Proceedings of Deep Learning Inside Out (DeeLIO 2022) : 3e atelier sur l’extraction et l’intégration des connaissances pour les architectures de deep learning, pages 100–114, Dublin, Irlande et en ligne, mai 2022. Association pour la linguistique computationnelle.
[16] Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Tam, Zhengxiao Du, Zhilin Yang et Jie Tang. P-tuning : L’ajustement des prompts peut être comparable à l’ajustement fin entre gammes et tâches. Dans les actes de la 60e réunion annuelle de l’Association for Computational Linguistics (Volume 2 : Courts Papers), pages 61–68, Dublin, Irlande, mai 2022. Association pour la linguistique computationnelle.
[17] Y. Lu, M. Bartolo, A. Moore, S. Riedel et P. Stenetorp. Prompts fantastiquement ordonnés et où les trouver : Surmonter la sensibilité à l’ordre des prompts en quelques shots. Dans les actes de la 60e réunion annuelle de l’Association for Computational Linguistics (Volume 1 : Long Papers), pages 8086–8098, Dublin, Irlande, mai 2022. Association pour la linguistique computationnelle.
[18] S. Min, X. Lyu, A. Holtzman, M. Artetxe, M. Lewis, H. Hajishirzi et L. Zettlemoyer. Repenser le rôle des démonstrations : Qu’est-ce qui rend l’apprentissage en contexte efficace? Dans les actes de la Conférence 2022 sur les méthodes empiriques en traitement du langage naturel, pages 11048–11064, Abu Dhabi, Émirats arabes unis, décembre 2022. Association pour la linguistique computationnelle.
[19] S. Mishra, D. Khashabi, C. Baral, C. Yejin et H. Hajishirzi. Reformuler les consignes pédagogiques dans le langage de GPTk. pages 589–612, 01 2022.
[20] A. Prasad, P. Hase, X. Zhou et M. Bansal. GrIPS : Recherche d’instructions sans gradient, basée sur des modifications, pour l’envoi de grands modèles de langage. ArXiv, abs/2203.07281, 2022.
[21] T. Shin, Y. Razeghi, R.L. Logan IV, E. Wallace et S. Singh. Autoprompt : Extraire des connaissances à partir de modèles de langage avec des invites générées automatiquement. pages 4222–4235, 01 2020.
[22] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi’ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave et G. Lample. LLaMA : Modèles de langage fondamentaux ouverts et efficaces, 02 2023.
[23] A. Wang, Y. Pruksachatkun, N. Nangia, A. Singh, J. Michael, F. Hill, O. Levy et S.R. Bowman. SuperGLUE : Un benchmark plus collant pour les systèmes de compréhension linguistique à usage général. Curran Associates Inc., Red Hook, NY, États-Unis, 2019.
[24] Y. Wang, S. Mishra, P. Alipoormolabashi, Y. Kordi, A. Mirzaei, A. Naik, A. Ashok, A.S. Dhanasekaran, A. Arunkumar, D. Stap, E. Pathak, G. Karamanolakis, H. Lai, I. Purohit, I. Mondal, J. Anderson, K. Kuznia, K. Doshi, K.K. Pal, M. Patel, M. Moradshahi, M. Parmar, M. Purohit, N. Varshney, P.R. Kaza, P. Verma, R.S. Puri, R. Karia, S. Doshi, S.K. Sampat, S. Mishra, A.S. Reddy, S. Patro, T. Dixit et X. Shen. Instructions surnaturelles : Généralisation via des instructions déclaratives sur 1600+ tâches de PLN. Dans les actes de la Conférence 2022 sur les méthodes empiriques dans le traitement du langage naturel, pages 5085–5109, Abu Dhabi, Émirats arabes unis, décembre 2022. Association pour la linguistique computationnelle.
[25] J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. Chi, Q. Le et D. Zhou. L’incitation à la chaîne de pensée suscite le raisonnement dans les grands modèles de langage. arXiv prépublication arXiv :2201.11903, 2022.
[26] J. Wei, J. Wei, Y. Tay, D. Tran, D. Webson, Y. Lu, X. Chen, H. Liu, D. Huang, D. Zhou, et T. Ma. Les modèles de langage plus larges font l’apprentissage en contexte différemment, 2023.
[27] J. Yoo, K. Perlin, S.R. Kamalakara et J.G.M Arau ́jo. Entraînement évolutif des modèles de langage utilisant jax, pjit et tpuv4. https://arxiv.org/pdf/2204.06514.pdf 2022.
[28] W. Yuan, G. Neubig et P. Liu. BARTScore : Évaluation du texte généré comme génération de texte. Dans M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang et J. Wortman Vaughan, éditeurs, Advances in Neural Information Processing Systems, volume 34, pages 27263–27277. Curran Associates, Inc., 2021.
[29] S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin, T. Mihaylov, M. Ott, S. Shleifer, K. Shuster, D. Simig, P. S. Koura, A. Sridhar, T. Wang et L. Zettlemoyer. OPT : Ouvrir des modèles de langage transformateurs pré-entraînés. arXiv : 2205.01068, 2022.







































































































