
Par Jonathan Woods
14 mars 2022
Cet article fait partie de notre série IA fiable. Dans le cadre de cette série, nous publierons un article par semaine autour de
- Interprétabilité
- Équité
- Gouvernance
Dans l’article de cette semaine, l’équipe d’innovation industrielle de Vector analyse les défis liés à l’interprétabilité en apprentissage automatique afin d’aider les organisations à réfléchir à leur gouvernance et à proposer des principes généraux pour la gouvernance de l’interprétabilité des modèles d’apprentissage automatique.
L’interprétabilité des modèles est un élément clé de la gouvernance de l’apprentissage automatique. La capacité à prédire de façon cohérente le résultat d’un modèle et à comprendre comment il en est arrivé est essentielle pour répondre à des questions importantes, notamment :
- Peut-on faire confiance au modèle qu’on utilise?
- Comprenons-nous ce que fait le modèle?
- Pouvons-nous expliquer comment le modèle en est arrivé à ses conclusions?
L’interprétabilité n’est pas une préoccupation nouvelle. La gouvernance des modèles logiciels traditionnels, « basés sur des règles », exige généralement la capacité de bien comprendre leur fonctionnement. Cependant, l’apprentissage automatique (ML) présente de nouveaux défis qui rendent l’interprétabilité beaucoup plus complexe et rendent les techniques conventionnelles pour y parvenir plus adaptées. En raison des caractéristiques uniques de l’apprentissage automatique, l’utilisation d’approches traditionnelles d’interprétabilité peut même être contre-productive, menant involontairement à des résultats néfastes et dégradant la confiance dans les systèmes d’apprentissage en général.
Il n’est pas difficile d’imaginer des contextes où des réponses claires sur le fonctionnement d’un modèle peuvent être essentielles. Les médecins et les patients peuvent exiger un haut degré d’interprétabilité pour appuyer les justifications des recommandations d’un modèle concernant les interventions médicales et les plans de traitement. Les entreprises de médias en ligne peuvent vouloir de la transparence lorsque des abus, des injustices ou d’autres pratiques indésirables liées au contenu sont susceptibles de survenir et d’être amplifiées. Les enquêteurs pourraient avoir besoin de savoir comment un modèle de véhicule autonome a pris des décisions ayant mené à un accident.
À première vue, une solution peut sembler intuitive : il suffit de rendre les modèles d’apprentissage automatique aussi interprétables que possible par défaut. Malheureusement, ce n’est pas si simple. Dans certains cas, augmenter l’interprétabilité nécessite un compromis avec la performance du modèle, et il n’existe pas de règle standard sur le moment où l’un doit être privilégié par rapport à l’autre. Pour comprendre ce problème, considérons l’hypothèse suivante (paraphrasée) proposée par le conseiller scientifique en chef de Vector, Geoffrey Hinton. Supposons qu’un patient ait besoin d’une opération et doive choisir entre un chirurgien ML qui est une boîte noire mais a un taux de guérison de 90% et un chirurgien humain avec un taux de guérison de 80%. Quel choix est le meilleur pour le patient? [1] Les cliniciens devraient-ils exiger une transparence totale du modèle afin de savoir exactement ce que le modèle fait tout au long de l’opération, même si cela signifie une performance réduite? Ou devraient-ils être prêts à renoncer à la transparence afin d’offrir au patient la meilleure chance d’un résultat positif?
Ce type de jugement devra être pris pour les applications d’apprentissage automatique dans l’industrie et dans la société en général. Le défi, c’est qu’il n’y a actuellement aucun consensus sur la bonne réponse – ni même vraiment sur la façon d’aborder la question.
Il est clair qu’un avenir avec une adoption généralisée du ML exigera une confiance implicite généralisée. Idéalement, le ML deviendra une technologie aussi fiable que l’électricité. Tout le monde sait que l’électricité représente des dangers, et pourtant personne ne s’inquiète de brûler sa maison s’ils allument les lumières. Des connaissances et des meilleures pratiques en matière d’atténuation des risques adaptées à l’apprentissage automatique seront nécessaires pour que la société atteigne ce niveau de confiance avec cette nouvelle technologie. Comprendre les difficultés et déterminer le bon niveau d’interprétabilité pour chaque cas d’utilisation en question – ainsi que les bonnes façons de l’atteindre – sera une partie cruciale de leur développement. L’alternative pourrait être un long chapitre où le ML sera relégué à des tâches à faible enjeu, laissant la valeur massive qu’il promet sur la table.
La première étape est de comprendre le défi. Dans cet article, l’équipe d’innovation industrielle du Vector Institute analyse les défis d’interprétabilité liés à l’apprentissage automatique afin d’aider les organisations à réfléchir à sa gouvernance. Les défis liés à l’industrie, aux objectifs, à la complexité et aux limites techniques sont abordés séparément avant que l’article ne présente des principes généraux pour la gouvernance de l’interprétabilité des modèles d’apprentissage automatique. Les idées contenues dans cet article ont été façonnées par les contributions de divers sponsors industriels du Vector Institute.
Défis liés à l’apprentissage automatique : Les pratiques traditionnelles d’interprétabilité ne sont pas à la hauteur
Les cadres de gouvernance des risques modèles incluent généralement un composant d’interprétabilité. Cependant, les pratiques souvent utilisées pour les logiciels conventionnels ne sont pas suffisamment fiables pour gérer efficacement le risque lorsqu’elles sont appliquées aux modèles d’apprentissage automatique. Considérons certains des défis liés à l’application des techniques typiques d’interprétabilité à l’apprentissage automatique :
- Interprétation du comportement global du modèle. Une connaissance approfondie et une compréhension approfondie de la structure, des hypothèses et des contraintes d’un modèle conventionnel peuvent suffire pour déterminer avec certitude son fonctionnement. Cependant, en apprentissage automatique, les sorties des modèles sont basées sur des interactions conditionnelles entre des caractéristiques dépendantes et indépendantes, ce qui rend souvent l’opération du modèle trop complexe pour être articulée simplement en se référant à un ensemble de règles. De nombreux modèles d’apprentissage automatique n’ont pas de coefficients explicites ni de tests de signification statistique pour une caractéristique donnée, ce qui rend exceptionnellement difficile la détermination des poids attribués à une caractéristique telle qu’elle apparaît dans divers calculs lors de l’exploitation du modèle. Cela limite la profondeur de compréhension d’un modèle simplement en connaissant sa conception.
- Interprétabilité des fonctionnalités. Avoir une compréhension complète de chaque caractéristique – c’est-à-dire chaque propriété individuelle ou variable indépendante utilisée comme entrée dans un système – peut contribuer à développer une compréhension complète du fonctionnement du modèle. Cependant, l’ingénierie automatisée des fonctionnalités gagne en popularité. Par exemple, les modèles génératifs peuvent créer leurs propres entrées. À mesure que cela se poursuit, il pourrait devenir plus difficile de comprendre complètement les fonctionnalités et d’utiliser cette compréhension pour éclairer le fonctionnement du modèle.
- Transparence de la solution. Traditionnellement, concevoir les détails techniques d’un modèle pour qu’ils soient transparents peut aider à déterminer comment un modèle arrive à son résultat. En apprentissage automatique, ces détails peuvent inclure le nombre de couches dans un réseau de neurones ou les nœuds et divisions d’un arbre de décision. Malheureusement, simplement connaître ces détails ne donne pas nécessairement assez d’informations sur la façon dont des prédictions précises sont faites.
- La capacité à reproduire de façon cohérente les résultats d’un modèle en utilisant les mêmes entrées est une méthode pour déterminer comment fonctionne un modèle. Cependant, pour l’apprentissage automatique, la complexité du modèle, la variabilité matérielle et le coût de calcul peuvent rendre la reproduction des résultats d’un modèle difficile et excessivement coûteuse.
Il est clair que répondre aux besoins d’interprétabilité de la gouvernance des modèles d’apprentissage automatique nécessitera de nouvelles techniques supplémentaires.
Ambiguïtés et incertitudes liées à l’interprétabilité de l’apprentissage automatique
En l’absence de normes, plusieurs défis compliquent le développement et l’inclusion de pratiques d’interprétabilité significatives dans le cadre de la gouvernance. La prise de conscience de chacun de ces défis est cruciale pour les organisations qui cherchent à déterminer leurs exigences et méthodes d’interprétabilité. Les principaux défis peuvent être divisés en quatre catégories. Ils sont :
- défis spécifiques à l’industrie;
- défis liés aux buts et aux objectifs;
- défis liés à la complexité des modèles; et
- des défis liés à la technique.
Les tableaux suivants présentent les préoccupations de chaque catégorie, décrivant les défis, leurs implications et leurs impacts potentiels sur les clients ou utilisateurs finaux.
Défis de l’industrie
Différentes industries auront des exigences différentes en matière d’explicabilité. Une industrie où la plupart des applications sont à faible enjeu – des applications comme la planification de la main-d’œuvre – peut ne pas exiger des normes strictes d’interprétabilité, car le risque de préjudice ou de conséquences inattendues est relativement faible. Cela dit, les normes d’interprétabilité ne servent pas seulement à réduire les préjudices, mais aussi à accroître la confiance dans l’apprentissage automatique en général, et la mesure dans laquelle cela doit être fait nécessite probablement une discussion et une négociation par les organisations et leurs parties prenantes au cas par cas.
Le tableau ci-dessous décrit certains des principaux défis au niveau de l’industrie que les entreprises devraient reconnaître lorsqu’elles envisagent comment l’interprétabilité s’intégrera dans la gouvernance de l’utilisation de leurs modèles d’apprentissage automatique.
Tableau 1 : Défis de l’industrie

Objectifs et défis d’approche
Le degré approprié d’interprétabilité du modèle peut dépendre de l’usage du modèle. Il existe souvent des cas où les capacités prédictives des modèles boîte noire dépassent largement celles des humains, et où s’en tenir à la production du modèle peut mener à des résultats de meilleure qualité. Modifier le modèle pour augmenter la transparence pourrait en réduire la performance. Dans ces cas, il faut réfléchir attentivement pour trouver le bon équilibre entre deux objectifs : à savoir, la transparence et la qualité des résultats. Il y a un exercice subjectif, qui dépendra des valeurs et des normes de l’organisation, de l’industrie dans laquelle elle opère et de la société en général.
Il y a d’autres enjeux qui pourraient influencer l’approche de l’interprétabilité. L’une d’elles est le degré auquel les organisations se sentent à l’aise de s’appuyer sur des services d'« apprentissage automatique explicables », qui sont annoncés comme pouvant fournir des comptes rendus complets du fonctionnement des modèles en boîte noire. Ces questions doivent être abordées avec un scepticisme sain. La conséquence d’une confiance mal placée dans un tel service pourrait être qu’un cas d’utilisation du modèle où l’interprétabilité devrait être priorisée ne soit pas due à une surconfiance dans un service d’apprentissage automatique explicable. Un deuxième problème est le risque d’activités malveillantes – y compris la manipulation et les attaques malveillantes – d’impacter les résultats du modèle. Si la possibilité est élevée ou conséquente, cela peut faire pencher la balance vers une plus grande priorisation de l’interprétabilité plutôt que de la performance.
Le tableau ci-dessous présente une description de chacun de ces enjeux ainsi que les impacts potentiels.
Tableau 2 : Objectifs et défis d’approche
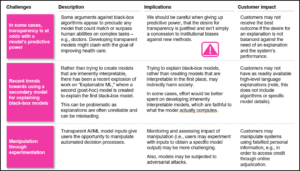
Défis liés à la complexité des modèles
Une performance plus élevée du modèle signifie souvent une complexité plus grande, ce qui entraîne souvent une interprétation réduite. Il peut simplement y avoir des limitations techniques au niveau d’interprétabilité que l’on peut attendre en employant un modèle particulièrement complexe.
Le tableau ci-dessous décrit les défis et impacts de la complexité des modèles.
Tableau 3 : Défis liés à la complexité des modèles
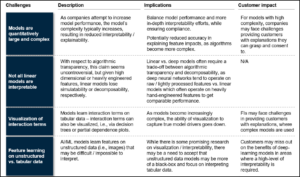
Limites techniques
Chaque technique utilisée pour l’interprétabilité a ses limites. Par exemple, l’interprétabilité post-hoc — interpréter le fonctionnement d’un modèle après coup via des explications en langage naturel ou des visualisations — peut fournir des informations utiles et peut être tentante à réaliser puisqu’elle ne nécessite pas de modifications au modèle qui pourraient diminuer la performance. Cependant, il faut être prudent : les humains peuvent être convaincus d’explications plausibles mais incomplètes – ou pire, entièrement erronées – parce qu’elles semblent correspondre à un schéma observé. Bien que les techniques existantes soient certainement utiles, elles ne doivent pas être confondues avec des méthodes infaillibles qui garantissent une interprétabilité
Le tableau 4 décrit diverses techniques d’interprétabilité post-hoc ainsi que leurs risques et contrôles.
Le tableau 5 décrit certaines limitations techniques et leurs implications.
Tableau 4. Techniques d’interprétabilité post-hoc ML
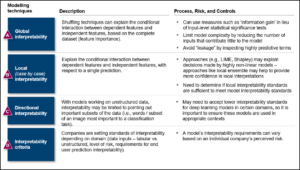
Tableau 5 : Limites techniques

Principes : Approcher l’interprétabilité dans l’ambiguïté
Compte tenu de ces défis, comment une organisation peut-elle aborder l’interprétabilité et l’inclure dans un cadre de gouvernance approprié? Voici des principes généraux sur l’approche de l’interprétabilité lors de la gestion du risque du modèle.
- Définir la gouvernance du modèle
Ce que signifie la gouvernance doit être défini par chaque organisation, en tenant compte de la taille de l’organisation, des valeurs corporatives, des normes de l’industrie et des intérêts des parties prenantes. Les contrôles doivent respecter les principes d’équité et d’acceptabilité sociale, et doivent inclure tous les aspects du cycle de vie du modèle – de l’idéation et le développement au déploiement et à la surveillance. Articuler ces principes et concepts est une première étape cruciale.
- Assurez-vous que l’interprétabilité fasse partie de la gouvernance
L’interprétabilité doit être prise en compte dans l’évaluation du risque du modèle d’apprentissage automatique et son adéquation dans l’approche de l’entreprise pour gouverner le risque du modèle plus largement. Le niveau d’interprétabilité souhaité pour un modèle doit être défini dès le début de sa conception afin de minimiser les compromis de performance et les impacts négatifs potentiels.
- Visez une connaissance approfondie des modèles
Bien que des défis existent pour acquérir une connaissance approfondie du fonctionnement d’un modèle ou des fonctionnalités générées par les modèles d’apprentissage automatique eux-mêmes, l’objectif devrait toujours être de maximiser la compréhension. Cela inclut la compréhension des sources de données ou entrées utilisées, de la structure du modèle, des hypothèses impliquées dans sa conception et des contraintes existantes. Ces connaissances sont essentielles pour démontrer la solidité conceptuelle et l’adéquation d’un modèle IA/ML à un cas d’utilisation.
- Lorsque l’interprétabilité est définitivement requise, optez pour des modèles intrinsèquement interprétables
Lorsqu’un cas d’utilisation et son contexte exigent que le fonctionnement d’un modèle soit transparent, il peut être plus prudent de concevoir des modèles intrinsèquement interprétables plutôt que d’appliquer des approches et techniques visant à atteindre l’interprétabilité post-hoc. Bien qu’un certain nombre d’approches et techniques puissent améliorer l’interprétabilité même dans les modèles d’apprentissage automatique, il peut être plus efficace de s’efforcer de concevoir des modèles intrinsèquement interprétables dans des scénarios à enjeux élevés ou à haut risque.
- Évitez une approche universelle
Les organisations devraient envisager d’utiliser différentes techniques selon le risque du modèle d’apprentissage automatique dans chaque application spécifique. Cela signifie éviter les approches prescriptives ou standardisées lorsqu’il s’agit de fixer des exigences d’interprétabilité des modèles, car celles-ci peuvent entraîner la sélection de modèles et technologies sous-optimaux.
- Engagez-vous à une surveillance continue et à un apprentissage continu
Apprendre à évaluer les risques avec précision, déterminer le compromis optimal entre la précision et la performance pour chaque cas d’usage et modèle, et décider des meilleures approches pour une organisation et une industrie demande du temps, une surveillance continue des résultats d’un modèle et un apprentissage continu. Les organisations devraient continuer à affiner leur compréhension des techniques, des risques et des résultats pour chaque modèle et application, afin d’acquérir une compréhension plus complète du rôle de l’interprétabilité dans la gouvernance et de la manière d’adapter leur approche dans divers contextes.
En résumé
L’apprentissage automatique représente une occasion formidable d’améliorer la productivité, l’innovation et le service à la clientèle dans tous les domaines. Cependant, la technologie comporte des risques et il n’existe pas de manuel standard pour les atténuer. Profiter du potentiel de ML signifie trouver une façon responsable d’avancer avec la technologie malgré cette incertitude.
La confiance – de la part des employés, des clients et du grand public – sera essentielle pour profiter pleinement des avantages que l’apprentissage automatique a à offrir. Pour instaurer cette confiance, les organisations doivent déterminer et adopter des pratiques appropriées de gouvernance du modèle d’apprentissage automatique, y compris celles liées à l’interprétabilité. Cela commence par comprendre les défis uniques que les modèles d’apprentissage automatique présentent pour les efforts d’interprétabilité, ainsi que les étapes pour déterminer le degré de transparence du modèle requis, les méthodes qui garantiront qu’il est fourni, et les considérations prises en compte pour déterminer quels compromis sont appropriés dans chaque cas d’usage.
[1] https://twitter.com/geoffreyhinton/status/1230592238490615816?lang=en















