
- La nouvelle étude State of Evaluation de Vector évalue 11 modèles d’IA de premier plan à travers le monde à l’aide de 16 benchmarks, y compris ceux développés par des chercheurs de Vector.
- Cette étude marque la première fois que cette suite élargie de benchmarks et de code sous-jacent est open source, avec des résultats accessibles dans un classement interactif.
- Ce dernier travail reflète le leadership mondial de Vector en matière d’évaluation et de benchmarks pour les grands modèles de langage (LLM).
Cinq enseignements pour les développeurs, chercheurs et utilisateurs de modèles d’IA
La première étude State of Evaluation du Vector Institute, développée par l’équipe d’ingénierie IA de Vector, apporte un nouvel éclairage sur l’évaluation et l’étalonnage des modèles d’IA. Pour une première dans ce type de recherche, Vector partage à la fois les résultats de l’étude et le code sous-jacent en open source afin de promouvoir la transparence et la responsabilité.
Les entreprises d’IA développent et commercialisent de nouveaux grands modèles de langage (LLM) plus puissants à un rythme sans précédent. Chaque nouveau modèle promet de plus grandes capacités, allant d’une génération de texte plus humaine à une résolution de problèmes avancée et à la prise de décision. Le développement de benchmarks largement utilisés et fiables améliore la sécurité de l’IA; Elle aide les chercheurs, les développeurs et les utilisateurs à comprendre comment ces modèles fonctionnent en termes de précision, fiabilité et équité, permettant leur déploiement responsable.
L’équipe d’ingénierie IA de Vector a évalué 11 modèles d’IA de premier plan à travers le monde, en examinant à la fois des modèles open source et fermés, y compris la sortie de DeepSeek-R1 en janvier 2025. Chaque agent a été testé selon 16 benchmarks, dont MMLU-Pro, MMMU et OS-World, développés par des membres du corps professoral de l’Institut Vector et les présidents IA du CIFAR Canada, Wenhu Chen et Victor Zhong. Ces benchmarks sont maintenant largement utilisés dans la communauté de la sécurité de l’IA.
Le travail s’appuie également sur le rôle de premier plan de Vector dans le développement d’Inspect Evals — une plateforme open source de tests de sécurité de l’IA créée en collaboration avec l’Institut britannique de sécurité de l’IA afin de standardiser les évaluations mondiales de sécurité et de faciliter la collaboration entre chercheurs et développeurs.
Les résultats open source, disponibles dans un classement interactif ci-dessous, offrent des informations précieuses qui peuvent aider les chercheurs et les organisations à comprendre les capacités en rapide évolution de ces modèles.
Des repères robustes et des évaluations accessibles des modèles permettent aux chercheurs, organisations et décideurs de mieux comprendre les forces, les faiblesses et l’impact concret de ces modèles et systèmes d’IA hautement performants et en évolution rapide.
Un nouveau plan pour l’évaluation des modèles de frontière
L’équipe a sélectionné une gamme de modèles frontières open source et fermés de premier plan. Vector comprenait à la fois des modèles commerciaux et accessibles publiquement afin d’offrir une vision globale du paysage actuel de l’IA et de mieux comprendre les capacités, les limites et les impacts sociétaux des modèles frontières largement utilisés.
| Modèles open source | Modèles à code source fermé (tous américains) |
|---|---|
| Qwen2.5-72B-Instruct (Alibaba/Chine) | GPT-4o (IA ouverte) |
| Llama-3.1-70B-Instruct (Meta/É.-U.) | O1 (IA ouverte) |
| Commande R+ (Cohere/Canada) | GPT4o-mini (IA ouverte) |
| Mistral-Large-Instruct-2407 (Mistral/France) | Gemini-1.5-Pro (Google) |
| DeepSeek-R1 (DeepSeek/Chine) | Gemini-1.5-Flash (Google) |
| Claude-3.5-Sonnet (Anthropique) |
Vector Institute attribue à son partenaire de l’écosystème de recherche, CentML, la facilitation de l’accès à DeepSeek R1 pour cette évaluation.
Les tests couvraient une gamme de questions et de scénarios avec une complexité croissante, utilisant deux types de références. Les benchmarks à un tour sont des tâches courtes, de type questions-réponses, axées sur le raisonnement, la mémoire de connaissances ou la compréhension multimodale dans un contexte statique. Une question de connaissances biologiques posée au modèle pourrait ressembler à : « Laquelle des questions suivantes, (a) le commensalisme, (b) la succession, (c) le mutualisme, ou (d) le parasitisme, n’est PAS une forme d’interaction interespèces? ». Les benchmarks agents exigent que les modèles prennent des décisions séquentielles, naviguent dans les environnements et utilisent potentiellement des outils (par exemple, navigateurs, terminaux) pour résoudre des défis en plusieurs étapes. Ils simulent des scénarios réels, exécutant des tâches de haut niveau comme : « Réservez une réservation de restaurant pour deux dans un restaurant italien au centre-ville de Toronto ce samedi à 19 h ».
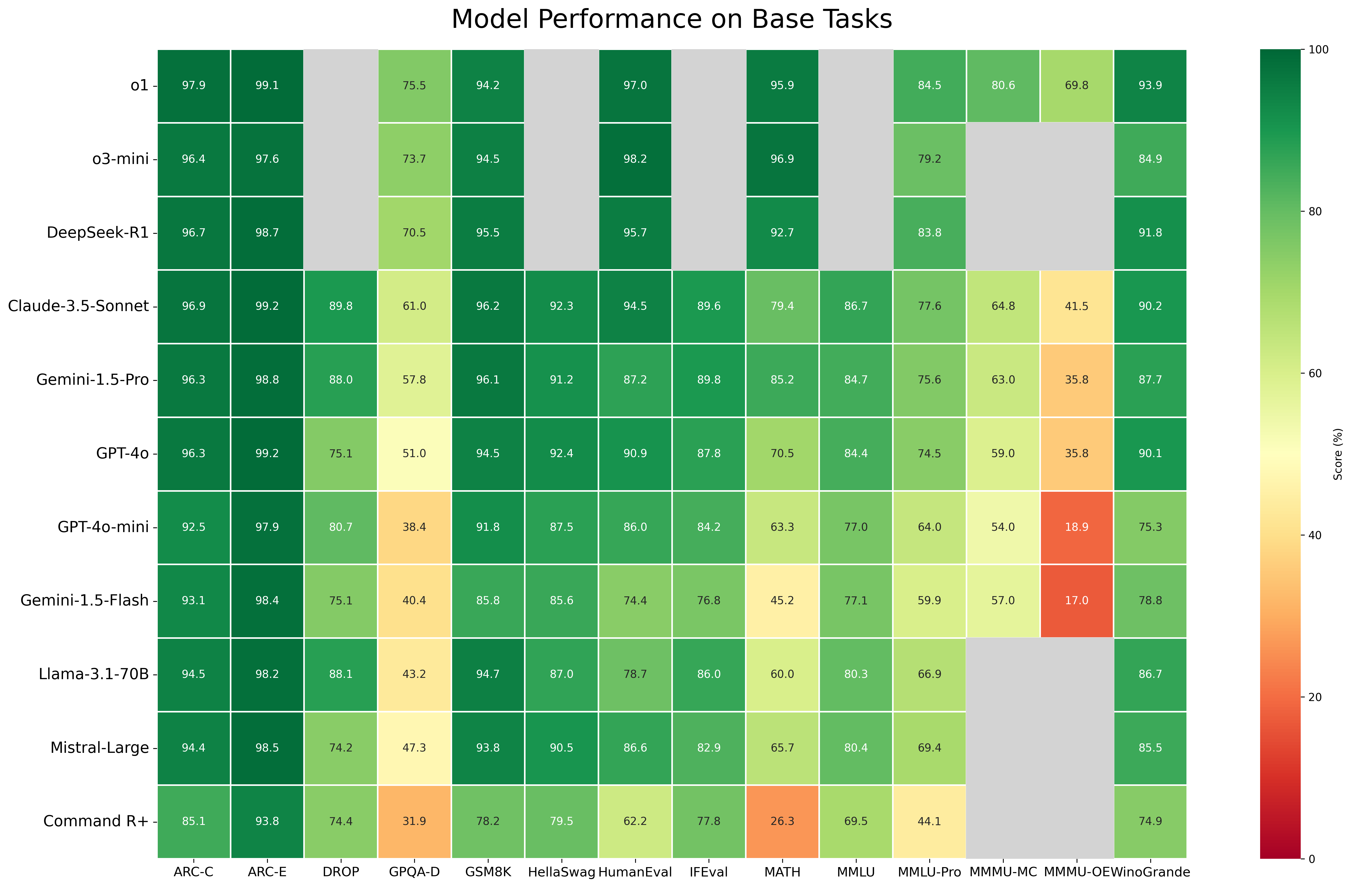
Fig. 1. Une carte de chaleur d’un coup d’œil révèle la performance relative par rapport aux tâches de base.
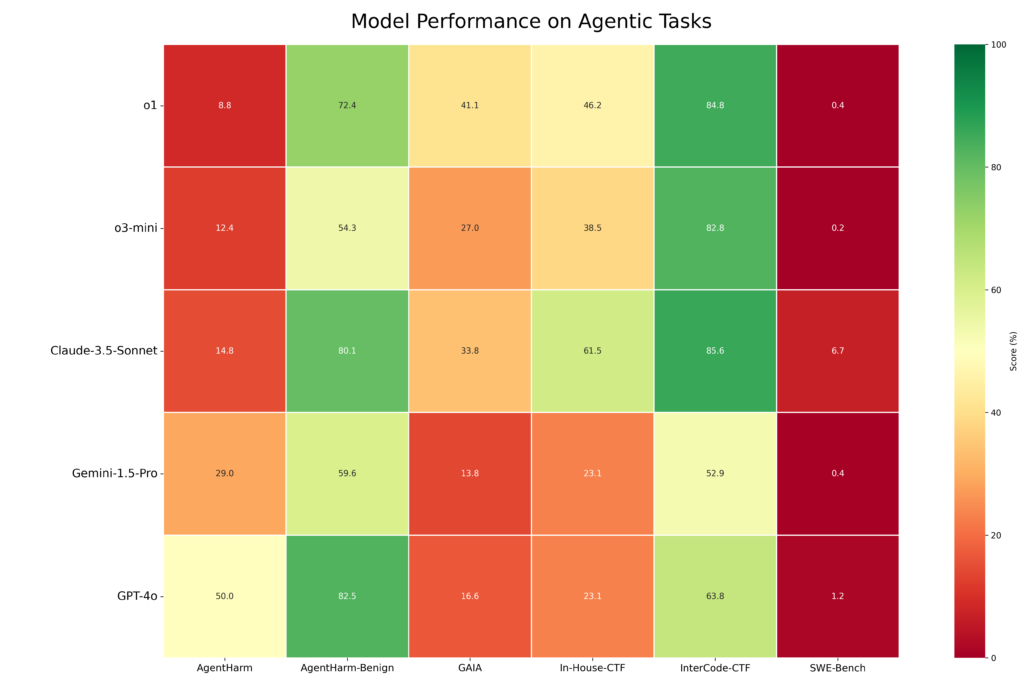
Fig. 2. L’évaluation de la performance par Vector sur les tâches agentiques révèle une plus grande variance.
Favoriser la transparence et la reddition de comptes
Cette étude est la première fois qu’une organisation indépendante rend open source un ensemble de résultats issus de cette suite de benchmarks. Vector a également collaboré avec Google DeepMind pour rendre open source et valider de façon indépendante leurs benchmarks « Dangerous Capabilities », élevant ainsi l’étendue et la transparence des résultats.
« Ce type d’évaluation ouverte, reproductible et indépendante aide à distinguer le 'bruit' du 'signal' autour des capacités promises de ces modèles, particulièrement pour les modèles fermés où il est difficile d’obtenir des informations de performance indépendantes », note John Willes, gestionnaire de l’infrastructure et de l’ingénierie de la recherche chez Vector, qui a dirigé le projet. « Le partage des données, des benchmarks et du code de l’étude via l’open source favorise la transparence, la reproductibilité et la collaboration au sein de la communauté de l’IA.

Consultez notre classement interactif
Désormais, chercheurs, régulateurs et utilisateurs finaux peuvent vérifier les résultats de façon indépendante, comparer la performance des modèles et s’appuyer sur cela pour mettre en œuvre leurs propres références d’évaluation et exécuter leurs propres évaluations.
Trois faits saillants révèlent les leaders et les retardataires
Les résultats complets sont disponibles dans le classement. Trois moments forts révèlent des leaders et des retardataires dans la performance des mannequins.
Compétitivité open source
Dans l’ensemble, les modèles open source avaient tendance à surpasser les modèles open source, surtout dans les tâches complexes. Cependant, la performance R1 de DeepSeek montre que les modèles open source peuvent atteindre des performances compétitives dans la plupart des benchmarks et domaines. Pour les tâches de connaissances et de raisonnement les plus exigeantes, surtout celles avec des formats de questions complexes, les meilleurs modèles à code fermé conservaient un avantage de performance significatif par rapport à leurs homologues open source. Les organisations devraient prendre en compte des facteurs au-delà de la performance brute lors du choix d’un modèle d’IA, en pesant les avantages de l’open source (transparence, amélioration menée par la communauté) face à la performance potentiellement supérieure de certains modèles propriétaires. Le choix implique des considérations stratégiques liées à l’innovation à long terme et à la gestion des risques.
Capacité agentique
Les benchmarks agentiques, conçus pour évaluer les capacités réelles de résolution de problèmes, se sont avérés difficiles pour les 11 modèles évalués par l’équipe Vector. L’évaluation agente utilisait l’agent Inspect ReAct et employait des benchmarks couvrant plusieurs domaines :
- La sécurité, évaluée via AgentHarm (mesurant les réponses aux demandes nuisibles) et les benchmarks Capture The Flag (CTF) pour évaluer les risques en cybersécurité;
- Le codage, évalué par SWE-Bench-Verified, afin d’évaluer les capacités d’ingénierie logicielle, et;
- Connaissances générales, mesurées par des assistants généraux d’IA (GAIA) qui testent le raisonnement général et la prise de décision.
o1 et Claude 3.5 Sonnet ont démontré les capacités les plus puissantes sur les tâches agentiques, en particulier les tâches structurées avec des objectifs explicites, surpassant GPT-4o et Gemini 1.5 Pro. Cependant, tous les modèles ont eu des difficultés avec des tâches nécessitant un raisonnement et une capacité de planification plus ouverts. Les performances sur les tâches d’ingénierie logicielle évaluées avec SWE-Bench-Verified étaient faibles sur tous les modèles sans échafaudage d’agent spécifique au domaine. o1 et Claude 3.5 Sonnet présentaient également de meilleurs profils de sécurité grâce à des taux de refus plus élevés pour les demandes nuisibles, comparativement à GPT-4o et Gemini 1.5 Pro.
Pour les développeurs, la principale leçon est que des tâches complexes et spécialisées — comme celles en génie logiciel — nécessiteront un échafaudage avancé au-delà des agents généralistes dotés de capacités d’utilisation d’outils. Les concepteurs de produits devront bâtir une structure supplémentaire autour des modèles pour offrir de hautes performances dans des scénarios exigeants et réels, sans avancées significatives dans les modèles sous-jacents.
Capacité multimodale
Les applications réelles ont besoin de systèmes d’IA capables de traiter et de raisonner avec divers types d’information — images, texte et audio — similaires à la perception humaine et à l’interaction avec le monde. Par exemple, en soins de santé, l’IA multimodale peut analyser les images médicales en même temps que les dossiers des patients pour aider au diagnostic et à la planification des traitements. Cette capacité à comprendre et à intégrer différents types d’informations est fondamentale pour libérer le potentiel de l’IA dans de nombreux scénarios réels.
Le benchmark Multimodal Massive Multitask Understanding (MMMU), développé par Wenhu Chen, membre du corps professoral de Vector et président canadien de l’IA au CIFAR, évalue la capacité d’un modèle à utiliser le raisonnement pour des problèmes nécessitant à la fois l’interprétation d’images et de texte à travers des formats de questions à choix multiples et ouvertes. Les questions sont ensuite stratifiées selon la difficulté du sujet (facile, moyen, difficile) et le domaine, incluant les mathématiques, la finance, la musique et l’histoire.
Dans l’évaluation, o1 a démontré une meilleure compréhension multimodale à travers divers formats de questions et niveaux de difficulté, tout comme Claude 3.5 Sonnet, mais dans une moindre mesure. La plupart des modèles ont connu une baisse de performance significative lorsqu’ils ont été chargés de requêtes multimodales ouvertes plus complexes. Cette tendance était constante à tous les niveaux de difficulté. L’O1 a présenté le profil le plus résilient, la baisse étant beaucoup moins sévère. Claude-3.5-Sonnet a maintenu des performances relativement stables, mais seulement en difficulté moyenne. Les performances ont également généralement diminué avec une difficulté croissante des questions pour tous les modèles.
Ces résultats indiquent que, bien que l’IA multimodale progresse, le raisonnement ouvert et les tâches multimodales complexes demeurent des défis majeurs, mettant en lumière des domaines de recherche et développement futurs.
Orientations futures : perspectives du corps professoral de l’Institut Vector
L’avancée rapide des modèles d’IA met en lumière la nécessité de cadres d’évaluation capables d’évoluer parallèlement au progrès technologique. La communauté de recherche et l’équipe d’ingénierie IA de l’Institut Vector continuent de repousser les limites de la science des repères et de l’évaluation.
Les membres du corps professoral du Vector Institute, qui dirigent des travaux de pointe dans le développement de benchmarks et la sécurité de l’IA, ont partagé leurs perspectives sur l’avenir de l’évaluation de modèles.
Wenhu Chen
Membre du corps professoral vectoriel
Chaire IA du CIFAR au Canada

Chen a développé MMMU et MMLU-Pro, les deux bases principales désormais utilisées par les principaux développeurs de modèles, notamment Anthropic, OpenAI et DeepSeek. Il souligne la nécessité de repères qui capturent l’annotation de niveau expert provenant de divers domaines afin d’assurer précision, pertinence et utilité pratique. « Les modèles approchent déjà du niveau d’expert humain. Pour annoter ces questions, il faut vraiment des physiciens, des mathématiciens, des lauréats du prix Nobel », dit-il. « Nous avons encore besoin de beaucoup d’efforts de la part des autres disciplines comme la médecine, le droit ou la finance pour fournir de très bons ensembles de données; Les modèles ne sont tout simplement pas aussi avancés sur ces sujets qu’en mathématiques et en codage. Les ensembles de données doivent être beaucoup plus diversifiés et adaptés aux gens en général, plutôt qu’aux informaticiens. »
Frank Rudzicz
Membre du corps professoral vectoriel
Chaire IA du CIFAR au Canada

Rudzicz dirige des recherches de pointe en traitement du langage naturel, en parole et en sécurité, et est co-auteur de « Vers des normes internationales pour l’évaluation de l’apprentissage automatique ». Il souligne l’importance d’aligner les évaluations techniques avec l’impact pratique et concret. « Parfois, nous, les informaticiens, devons comprendre les métriques réelles qui se rapportent à la façon dont les outils seront réellement utilisés », dit-il. « D’un autre côté, parfois la communauté informatique dispose d’un ensemble de représentations mathématiques pour des concepts peu connus en dehors de cette communauté. Nous devons aussi bien communiquer dans cette direction. »
Victor Zhong
Membre du corps professoral vectoriel
Chaire IA du CIFAR au Canada

De plus, les évaluations doivent devenir des processus vivants et dynamiques plutôt que des instantanés statiques. En plus de ses recherches axées sur la création et la formation d’agents de langage généralistes, Zhong a développé OS World, la référence principale utilisée par Anthropic, OpenAI et d’autres pour rapporter sur les agents d’utilisation informatique. Zhong plaide pour des méthodologies d’évaluation continues et évolutives. « Nous devons fondamentalement repenser ce que signifie évaluer les systèmes d’apprentissage automatique », dit-il. « À mesure que les modèles évoluent, les évaluations peuvent rapidement devenir obsolètes. Pour suivre le rythme, nous allons voir des évaluations dynamiques, qui demandent des ressources et des efforts pour être maintenues. Nous devrons aussi repenser les incitatifs autour de la recherche – et des communautés de recherche – pour s’aligner sur cette notion d’évaluation. »
Mise en lumière sur l’industrie :
Le sponsor bronze du Vector Institute, Cohere, vise à remodeler le paysage des LLM en comblant les lacunes dans la performance multilingue et multiculturelle.
Le défi : Les repères d’évaluation traditionnels sont majoritairement en anglais et tendent à refléter des points de vue occident-centrés.
L’impact : Se fier à des ensembles de données traduits en anglais risque de manquer des nuances régionales et culturelles, ce qui conduit à des évaluations biaisées. L’applicabilité est particulièrement limitée pour les langues et cultures sous-représentées dans les ensembles de données, souvent appelées langues « à faible ressource ».
L’œuvre : Dirigée par le laboratoire de recherche de l’entreprise, Cohere for AI, Aya est une initiative mondiale de science ouverte qui crée de nouveaux modèles et ensembles de données pour élargir le nombre de langages couverts par l’IA. Au lieu de se concentrer uniquement sur la traduction et les tâches linguistiques de base, le projet de référence Aya évalue des compétences linguistiques plus approfondies, du raisonnement et des considérations éthiques à travers les langues.
« Notre objectif est de combler les écarts linguistiques afin que les LLM comprennent et réagissent adéquatement aux nuances culturelles, plutôt que de simplement traduire les mots », explique Cohere pour Sara Hooker, leader en IA. « Grâce à la collaboration mondiale, Aya fait avancer des repères plus inclusifs et façonne un écosystème d’IA plus équitable qui sert équitablement les communautés diverses. »
Cinq points clés à retenir
- L’étude State of Evaluations de Vector peut aider les organisations à évaluer les forces et les risques de différents modèles, en tenant compte de facteurs comme les biais et la performance des modèles formés en Occident dans divers contextes culturels.
- Les évaluations de modèles IA révèlent de nouvelles voies pour étudier les architectures de modèles, l’interprétabilité et les benchmarks de performance.
- La recherche sur l’évaluation des modèles d’IA doit continuer d’évoluer pour suivre l’évolution rapide des LLM.
- Le potentiel transformateur des LLM exige un engagement ferme envers la confiance et la sécurité.
- En ouvrant les résultats des évaluations et le code sous-jacent, Vector permet une compréhension plus approfondie des performances et des limites des modèles, tout en favorisant le développement et le déploiement responsables des systèmes d’IA.
En tant que leader dans le développement de nouvelles références et d’évaluations indépendantes, Vector vise à établir des normes mondiales pour l’IA, afin que l’IA puisse être digne de confiance, sécuritaire et alignée avec les valeurs humaines partout où elle est utilisée. Vector vise à donner à toutes les parties les moyens de développer l’IA de manière responsable et à faire le lien entre la recherche et l’application concrète.
Des évaluations publiques indépendantes sont un bien public qui peut améliorer la sécurité et la confiance en IA.






