
12 oct. 2022
Les blogues Vector AI Engineering offrent des perspectives sur l’apprentissage automatique appliqué et le travail d’ingénierie au sein de l’équipe d’ingénierie IA. Ils sont rédigés par le personnel d’ingénierie IA en collaboration avec les étudiants, postdoctorants, professeurs et affiliés de l’Institut Vector. Ainsi que des partenaires industriels.
Les contributeurs de Vector incluent : John Jewell, Shihao Ma, Deval Pandya
À mesure que les images satellites haute résolution deviennent de plus en plus accessibles dans les domaines public et privé, plusieurs applications bénéfiques qui tirent parti de ces données sont activées. L’extraction des empreintes des bâtiments dans les images satellites est un élément central de nombreuses applications en aval de l’imagerie satellite, telles que l’aide humanitaire et la réponse aux catastrophes.
Ce travail propose une étude comparative des méthodes basées sur l’apprentissage profond pour construire l’extraction d’empreintes dans des images satellites.
Qu’est-ce que la segmentation sémantique?
La segmentation sémantique est une sous-classe de la segmentation d’image où les pixels sont regroupés selon leur classe. Il joue un rôle crucial dans un large éventail d’applications telles que la conduite autonome (par exemple, voitures autonomes ou trains autonomes), l’analyse géospatiale (par exemple, l’extraction d’empreintes de bâtiments) et la segmentation d’images médicales (par exemple, la découverte de marqueurs biomédicaux). L’objectif de la segmentation sémantique est d’étiqueter chaque pixel d’une image avec une classe, en partitionnant effectivement les pixels de l’image en groupes selon le type d’objet. En raison de la nature à haute dimension de l’espace d’entrée et de sortie, la segmentation sémantique a traditionnellement été une tâche très difficile en vision par ordinateur [2]. Heureusement, les approches récentes d’apprentissage profond supervisé ont obtenu une performance robuste en segmentation sémantique sur une variété de benchmarks exigeants [3]. Ces approches utilisent de grands ensembles de données d’images avec des étiquettes pixel par pixel correspondantes pour entraîner les réseaux de neurones en mettant à jour itérativement les paramètres du modèle afin de minimiser une perte différentiable qui caractérise la différence entre les prédictions et les étiquettes. Lors de l’inférence, de nouveaux échantillons sont envoyés au réseau qui produit une carte de segmentation avec la même résolution spatiale que l’image d’entrée qui encode l’étiquette de chaque pixel.
Extraction de l’empreinte des bâtiments
Inspirés par la performance impressionnante des modèles de segmentation sémantique, des efforts importants ont été déployés pour transférer le succès des méthodes de segmentation sémantique basées sur l’apprentissage profond à l’extraction d’empreintes des bâtiments. L’extraction de l’empreinte des bâtiments est un cas particulier de segmentation sémantique qui consiste à segmenter les empreintes des bâtiments dans des images satellites.
Ensemble de données
Le jeu de données SpaceNet Building Detection V2 [1] est utilisé pour évaluer différentes approches dans cette étude. Cet ensemble de données contient des images satellites haute résolution et des étiquettes correspondantes qui spécifient l’emplacement des empreintes des bâtiments. L’ensemble de données comprend 302 701 étiquettes de bâtiments provenant de 10 593 images satellites multispectrales de Las Vegas, Paris, Shanghai et Khartoum. Les libelles sont binaires et indiquent si chaque pixel est en construction ou en arrière-plan, comme on peut le voir à la Figure 1.

Méthodes explorées
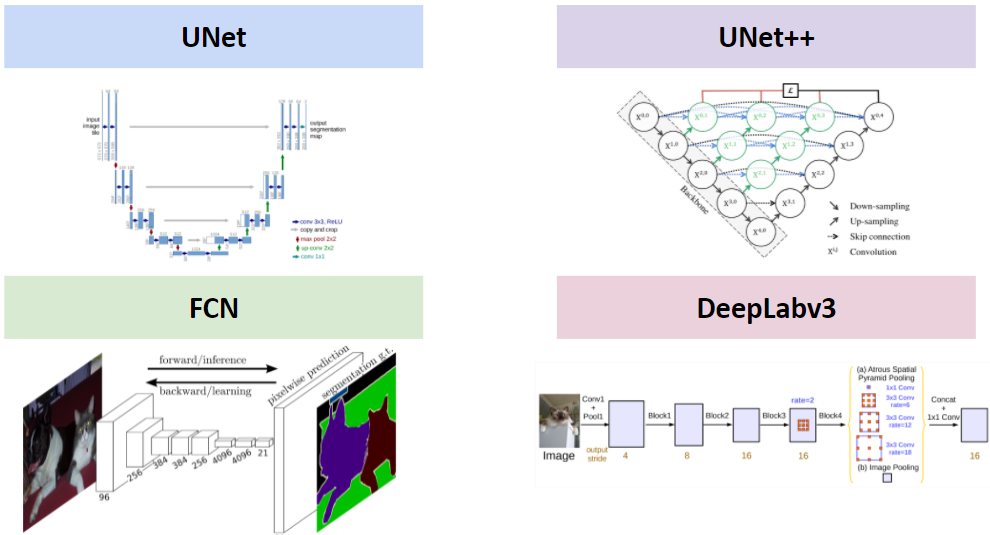
Les quatre approches de segmentation sémantique explorées incluent : U-Net [3], U-Net++ [7], Fully Convolutional Networks (FCN) [5] et DeepLabv3 [10]. Ces architectures sont représentées à la Figure 2. Pour FCN et DeepLabv3, deux variantes de l’architecture avec des backbornes différentes (Resnet-50 et Resnet-100) sont incluses. Ainsi, au total, six approches sont évaluées pour la tâche d’extraction de l’empreinte dans des images aériennes.
U-Net : U-Net est une architecture encodeur-décodeur pour la segmentation sémantique. L’encodeur se compose d’un chemin contractant pour capturer le contexte et le décodeur d’un chemin expansif permettant une localisation précise [3]. Les connexions sautées copient les cartes de caractéristiques de l’encodeur vers les couches du décodeur au même niveau que la hiérarchie de résolution spatiale. Cela permet le flux d’informations de haut niveau qui peuvent être perdues dans la sortie basse dimensionnelle de l’encodeur [3].
U-Net++ : U-Net++ est une architecture encodeur-décodeur pour la segmentation sémantique qui s’appuie sur U-Net en reliant l’encodeur et le décodeur à travers une série de chemins de saut denses et imbriqués. Les voies de saut repensées visent à réduire l’écart sémantique entre les cartes de caractéristiques des sous-réseaux encodeur et décodeur [7]. Comparé à l’architecture U-Net, U-Net++ offre non seulement des connexions directes ou sautées entre les couches de downsampling et up-sample, mais aussi des connexions convolutionnelles, qui peuvent transmettre plus de fonctionnalités dans les couches de suréchantillonnage.
FCN : FCN mappe des images d’entrée de taille arbitraire en applications sémantiques prédites en utilisant uniquement des couches convolutionnelles [5]. Les couches d’upsampling intégrées au réseau sont utilisées pour faire des prédictions pixel par pixel en augmentant la résolution spatiale des caractéristiques générées par l’épine dorsale du réseau jusqu’à la hauteur et la largeur de la sortie. Une fois suréchantillonnée, l’information sémantique des cartes de caractéristiques basse résolution est combinée avec les informations d’apparence des cartes de caractéristiques haute résolution pour produire des segmentations précises. Un FCN avec une colonne vertébrale Resnet-50 (FCN-50) et une colonne vertébrale Resnet-101 (FCN-101) sont tous deux évalués dans la section des expériences. Les backbones sont pré-entraînés à l’aide du jeu de données de segmentation sémantique COCO train2017 [22] et affinés pour la tâche d’extraction de l’empreinte du bâtiment.
DeepLabv3 : DeepLabv3 est une architecture encodeur-décodeur pour segmentation sémantique qui exploite des filtres convolutifs dilatés pour augmenter le champ réceptif du réseau et prévenir un sous-échantillonnage excessif [10]. Un module de pooling pyramidal spatial est utilisé pour capturer le contexte à plusieurs résolutions, ce qui est utile pour localiser des objets de différentes tailles. Les couches convolutionnelles standard sont prises en compte dans des convolutions séparables en profondeur suivies de convolutions ponctuelles. Cela réduit considérablement les opérations en virgule flottante par couche convolutionnelle tout en maintenant l’expressivité du réseau. Les deux variantes de DeepLabv3, avec une colonne vertébrale Resnet-50 (DLV3-50) et une colonne vertébrale Resnet-101 (DLV3-101), sont évaluées dans la section des expériences. Les colonnes vertébrales sont pré-entraînées à l’aide du jeu de données de segmentation sémantique COCO train2017 [22] et affinées pour la tâche d’extraction de l’empreinte du bâtiment.
Résultats
L’intersection sur Union, comme illustré à la Figure 3, est une métrique d’évaluation utilisée pour mesurer la précision d’un détecteur d’objets sur un ensemble de données particulier.

En examinant cette équation, vous pouvez voir que l’intersection sur l’union est simplement un rapport. Dans le numérateur, nous calculons l’aire de chevauchement entre la boîte englobante prédite et la boîte englobante à vérité fondamentale. Le dénominateur est l’aire d’union, ou plus simplement, l’aire englobée à la fois par la boîte englobante prédite et la boîte englobante de la vérité fondamentale. Diviser l’aire de chevauchement par l’aire d’union donne notre score final — l’Intersection sur Union (IoU)
L’IoU de chaque méthode sur l’ensemble de test est indiquée dans le Tableau 1. Le DLV3-101 obtient les meilleures performances avec un IoU de 0,7734, suivi de près par le DLV3-50, FCN-50 et FCN-101. U-Net et U-Net++ performent comparativement moins bien avec un IoU de 0,5644 et 0,6554 respectivement. L’écart de performance s’explique par le fait que FCN-50, FCN-101, DLV3-50 et DLV3-100 bénéficient de la pré-formation, alors que U-Net et UNet++ ne bénéficient pas. Cet écart de performance est également visible à la Figure 4, qui montre la perte de train et de validation de chaque méthode à travers les époques. Les méthodes qui exploitent le préentraînement permettent d’obtenir de meilleures performances tant sur le train que sur le jeu de validation dès le début de l’entraînement. La perte de validation commence à stagner après seulement quelques époques, ce qui suggère que l’entraînement est terminé et devrait être arrêté tôt pour éviter le sur-ajustement. Alternativement, U-Net et U-Net++ subissent des pertes de train et de validation qui diminuent constamment au cours de l’entraînement. Cela souligne que les modèles qui exploitent le préentraînement convergent plus rapidement vers l’ensemble optimal de paramètres, en plus d’offrir de meilleures performances.
| Modèle | IoU |
| U-Net | 0.5664 |
| U-Net++ | 0.6554 |
| FCN-50 | 0.7455 |
| FCN-101 | 0.7472 |
| DLV3-50 | 0.7612 |
| DLV3-101 | 0.7734 |

Les résultats qualitatifs sont disponibles à la Figure 5, qui montre un exemple d’image d’entrée, une étiquette de vérité du terrain et une carte sémantique prédite pour chaque méthode. La qualité de prédiction des méthodes est comparable aux résultats quantitatifs, mais la performance est impressionnante dans tous les domaines. Ces méthodes permettent de générer des cartes sémantiques précises dans des scènes densément peuplées d’empreintes de bâtiments. De plus, les cartes sémantiques prédites dans des scènes peu peuplées avec des empreintes de bâtiments sont robustes face aux faux positifs, même dans les cas où des routes, des stationnements ou d’autres structures sont présents. Une analyse préliminaire de l’importance de l’architecture du modèle conditionnée par le préentraînement donne des résultats intéressants. La performance entre les méthodes qui exploitent le pré-entraînement est similaire, même entre différentes architectures et backbones. Inversement, lorsqu’on considère la performance des méthodes qui ne tirent pas parti du préentraînement, U-Net++ surpasse largement U-Net. Bien que cela justifie d’autres expériences pour valider, une hypothèse est que l’architecture du modèle devient moins pertinente à mesure que la quantité de préentraînement augmente.

Conclusion
Dans cette étude, nous avons entraîné et évalué plusieurs modèles de segmentation sémantique de pointe utilisant l’ensemble de données SpaceNet, dont U-Net, UNet++, FCN et DeepLabv3. Nos résultats ont montré que DeepLabv3 avec une colonne vertébrale Resnet-101 est l’approche la plus précise pour construire l’extraction d’empreintes parmi les modèles que nous avons explorés. Les modèles qui tirent parti du préentraînement (c.-à-d. FCN-50, FCN-101, DLV3-50 et DLV3-101) obtiennent une précision plus élevée et nécessitent un entraînement minimal comparativement aux modèles sans préentraînement (c’est-à-dire U-Net et UNet++). Cette étude implique qu’il convient d’appliquer l’apprentissage par transfert pour la tâche d’extraction d’empreintes de bâtiments à l’aide d’images satellites.
Ressources
[1] Un ensemble de données de télédétection et une série de défis.
[2] Segmentation d’images à l’aide de l’apprentissage profond : un sondage
[3] U-net : Réseaux convolutionnels pour la segmentation d’images biomédicales.
[5] Réseaux entièrement convolutionnels pour la segmentation sémantique.
[7] Unet++ : une architecture u-net imbriquée pour la segmentation d’images médicales
[10] Repenser la convolution atroce pour la segmentation sémantique de l’image.
[12] Apprentissage résiduel profond pour la reconnaissance d’images.
[15] Réseaux neuronaux convolutionnels entièrement résiduels pour la segmentation d’images aériennes.







































































































