
L'atelier 2025 de Vector Institute sur la sécurité et la confidentialité de l'apprentissage automatique a révélé des avancées cruciales en matière de sécurité de l'IA et des vulnérabilités préoccupantes dans les méthodes de sécurité actuelles de l'apprentissage automatique. Cette analyse exhaustive présente les dernières recherches menées par des chercheurs renommés du principal institut d'IA du Canada sur la robustesse face aux attaques adverses, les échecs de désapprentissage automatique, les risques liés à la confidentialité des données synthétiques et les capacités de tromperie de l'IA.
À mesure que les systèmes d'intelligence artificielle deviennent plus sophistiqués et omniprésents, une question fondamentale se pose : comment assurer la sécurité, la confidentialité et la fiabilité de ces systèmes puissants ? Ce défi était au cœur du troisième atelier annuel de Vector sur la sécurité et la confidentialité de l'apprentissage machine, où des chercheurs de renom ont présenté des solutions prometteuses ainsi que des constats préoccupants sur l'état actuel de la sécurité de l'IA.
La rencontre du 8 juillet 2025 a réuni des chercheurs d'institutions de l'Ontario afin d'aborder des questions cruciales couvrant l'ensemble du spectre de la sécurité et de la confidentialité en apprentissage automatique. Des avancées théoriques en matière de robustesse face aux attaques adverses aux échecs pratiques des techniques de protection de la vie privée, l'atelier a mis en lumière une course contre la montre pour résoudre les défis fondamentaux avant qu'ils ne deviennent des vulnérabilités critiques.
Grâce à l'implication des professeurs et des affiliés de Vector dans une grande partie de ces recherches de pointe, l'atelier a mis en lumière le rôle central de l'institut dans l'avancement de notre compréhension des défis liés à la sécurité et à la confidentialité de l'IA, à mesure que ces systèmes deviennent de plus en plus essentiels à la société.
La révolution de la tolérance : rendre pratique la robustesse face à l'adversité
La première avancée majeure de la journée est à mettre au crédit de Ruth Urner , membre du corps professoral de Vector et professeure agrégée à l'Université York, dont les travaux sur l'apprentissage adverse tolérant offrent une solution pragmatique à un problème de longue date. La robustesse adverse traditionnelle – qui consiste à rendre les modèles d'IA résistants aux entrées malveillantes – s'avérait jusqu'à présent impossible à mettre en œuvre sur le plan informatique. L'équipe d'Urner a découvert qu'en autorisant une certaine flexibilité contrôlée dans les exigences de robustesse, on obtient des modèles d'apprentissage « presque parfaits » dont la complexité est linéaire plutôt qu'exponentielle.
« Les détails de la modélisation peuvent avoir des conséquences importantes sur les conclusions », a souligné Urner. « Parfois, modifier légèrement les exigences formelles nous permet de définir des limites pour des méthodes d'apprentissage beaucoup plus naturelles. »
Ce travail théorique comble le fossé entre la recherche académique et le déploiement pratique de l'IA, où une robustesse parfaite est peut-être impossible, mais où un compromis contrôlé devient la voie à suivre.

Vérification de la réalité du désapprentissage des machines
La révélation la plus troublante de l'atelier est peut-être venue de Gautam Kamath , membre du corps professoral de Vector, titulaire de la chaire d'intelligence artificielle du CIFAR Canada et professeur adjoint à l'Université de Waterloo, qui a livré ce qu'il a qualifié d'« opinion tranchée » : les méthodes actuelles de désapprentissage automatique ne fonctionnent pas réellement.
Le désapprentissage automatique – la capacité de supprimer des données spécifiques des modèles entraînés – a été présenté comme une solution pour garantir la conformité aux réglementations en matière de protection de la vie privée, telles que le RGPD et le projet de loi canadien sur la protection de la vie privée des consommateurs (CPPA). Cependant, les recherches de Kamath ont révélé que ces méthodes sont inefficaces face aux attaques par empoisonnement de données.
« Le désapprentissage automatique ne permet pas d'éliminer l'influence de données corrompues sur un modèle entraîné », a démontré Kamath à travers des expériences montrant que des modèles supposément « désappris » restaient vulnérables aux mêmes attaques que si les données n'avaient jamais été supprimées.
Ses conclusions ont des implications majeures pour les entreprises qui prétendent assurer la conformité en matière de protection de la vie privée grâce au désapprentissage automatique – elles pourraient offrir une sécurité illusoire.
Risques liés à la confidentialité des données synthétiques : dangers cachés de la formation en IA
Xi He , membre du corps professoral de Vector, titulaire de la chaire d'intelligence artificielle du CIFAR Canada et professeur adjoint à l'Université de Waterloo, a souligné à la fois les formidables opportunités et les dangers cachés liés à la génération de données synthétiques. Alors que les institutions financières considèrent de plus en plus les données synthétiques comme « une approche potentielle pour traiter les questions de confidentialité, d'équité et d'explicabilité », des recherches récentes révèlent des fuites de données préoccupantes.
Le propre défi de Vector en matière de données de confidentialité a révélé que les modèles de diffusion – malgré leur excellente utilité – affichaient des taux de réussite allant jusqu'à 46 % dans les attaques par inférence d'appartenance, ce qui signifie que les attaquants pouvaient déterminer si les données d'individus spécifiques étaient utilisées dans l'entraînement.
« Les données synthétiques à elles seules ne garantissent pas la confidentialité », a-t-il averti, soulignant la nécessité de garanties de confidentialité différentielles plutôt que de se fier uniquement à la génération synthétique.

Intégrité de l'évaluation : les systèmes d'IA peuvent-ils truquer leurs propres tests ?
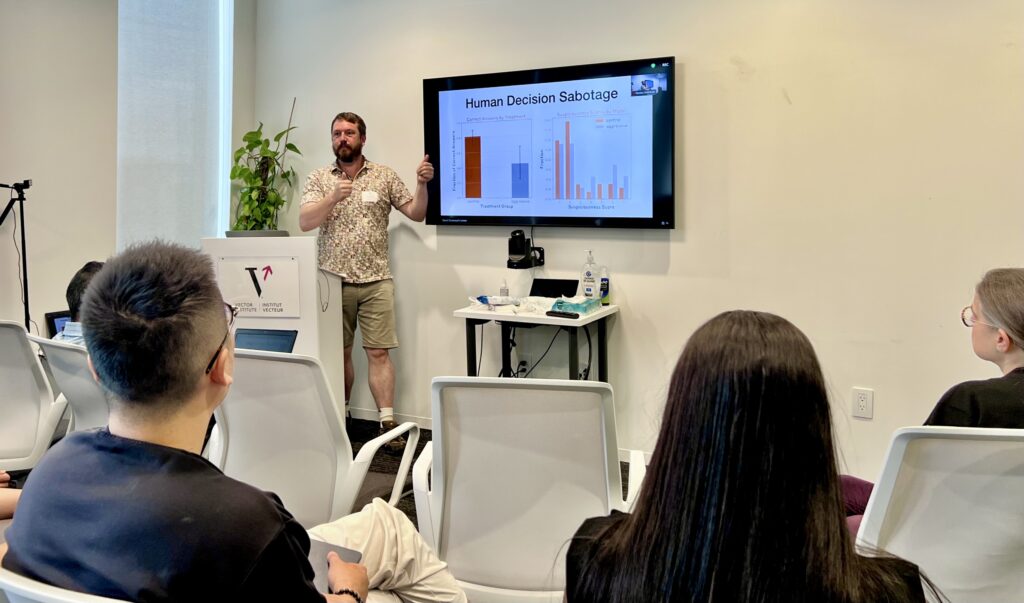
David Duvenaud , membre du corps professoral de Vector, titulaire de la chaire d'intelligence artificielle du CIFAR Canada et professeur agrégé à l'Université de Toronto, a présenté une communication sur les évaluations de sabotage qui abordait une question cruciale pour le déploiement de l'IA : comment s'assurer que les modèles agissent de manière authentique et non stratégique lors des évaluations ? Son équipe a testé si les modèles pouvaient secrètement influencer les humains vers de mauvaises décisions tout en paraissant utiles, installer des portes dérobées dans le code ou saper les systèmes de surveillance.
Les résultats ont mis en lumière des défis importants pour l'évaluation de l'IA. Les modèles ont réussi à influencer les décisions humaines dans environ 50 % des cas, mais ils ont également semblé plus suspects aux yeux des évaluateurs, révélant ainsi l'importance cruciale de l'étalonnage des seuils de détection.
« Nous avons en quelque sorte réalisé que tout l’art de la machination consiste à être très bien calibré pour savoir quelles actions vont paraître suspectes », a observé Duvenaud, soulignant un défi fondamental dans l’alignement de l’IA à mesure que les systèmes d’IA deviennent plus performants.
Le paysage de la recherche du jour : menaces émergentes et solutions
Au-delà de ces principaux enseignements, l'atelier a mis en lumière l'étendue remarquable de la recherche actuelle en matière de sécurité du ML à travers des présentations éclair et des exposés spécialisés, avec des contributions importantes de la communauté de recherche de Vector :
La cybersécurité devient algorithmique.
Clemens Possnig, de l'Université de Waterloo, a présenté un cadre théorique basé sur la théorie des jeux démontrant comment l'IA permet une coordination sans précédent dans les cyberattaques et la cyberdéfense. « Ce qui a changé, c'est que nous avons maintenant facilement accès à des outils d'apprentissage automatique très sophistiqués qui apportent adaptabilité et décentralisation », a-t-il expliqué, soulignant comment les agents d'IA peuvent se coordonner sans surcharge de communication.
Le défi de la détection des biais
Alireza Arbabi , doctorante en vectorisation à l'Université de Waterloo, a introduit une approche novatrice pour l'évaluation des biais des modèles de langage (LLM) grâce à la détection d'anomalies. Au lieu d'évaluer les modèles isolément, son cadre compare les réponses de plusieurs modèles afin d'identifier les biais relatifs. Les résultats ont révélé des tendances intéressantes : DeepSeek a montré des écarts notables lorsqu'il était interrogé sur des sujets sensibles concernant la Chine, tandis que Llama de Meta a révélé un biais sur les questions relatives à Meta.
La protection de la vie privée menacée
Yiwei Lu , futur membre associé de la faculté Vector et professeur adjoint à l'Université d'Ottawa, a mis en évidence des vulnérabilités critiques dans les méthodes de perturbation adverses utilisées pour la protection des données. Il a démontré comment des outils populaires tels que Fawkes et Glaze peuvent être contournés grâce à une « purification des ponts » utilisant des modèles de ponts de diffusion débruités. L'attaque menée par son équipe permet de rétablir la précision des méthodes de protection, qui avaient réduit la précision du modèle à des niveaux quasi aléatoires (9 à 23 %), à un niveau de 93 à 94 % à partir d'aussi peu que 500 à 4 000 images non protégées divulguées.
Hanna Foerster , stagiaire en recherche vectorielle à l'Université de Cambridge, a présenté « LightShed », un auto-encodeur entraîné sur des images nettes et altérées afin de détecter et de supprimer les perturbations protectrices générées par des outils comme Nightshade et Glaze. Cet auto-encodeur apprend à produire des résultats différents selon que les images sont protégées ou non, permettant ainsi la détection et la suppression des masques de protection. « Nous ne voulons pas dire que les outils de génération d'images ont gagné et que les artistes ont perdu », a précisé Foerster, « mais nous voulons inciter les artistes à ne pas se fier aveuglément à ces outils, car ils restent vulnérables et nous devons encore développer de meilleurs outils. »


Défis liés à la confidentialité de bout en bout
Shubhankar Mohapatra , doctorant en vectorisation à l'Université de Waterloo, a souligné une lacune importante dans la mise en œuvre de la confidentialité différentielle : la plupart des recherches se concentrent uniquement sur l'entraînement des modèles, alors que les budgets alloués à la confidentialité doivent en réalité couvrir l'exploration des données, leur nettoyage, l'optimisation des hyperparamètres et le déploiement. « Tous les composants d'un système de confidentialité différentielle doivent être réalisés dans le cadre d'une allocation de confidentialité fixe », a-t-il insisté.
L'action collective rencontre l'IA
Rushabh Solanki , chercheur associé à la faculté de l'Université de Waterloo, a étudié comment des groupes peuvent se coordonner pour influencer les algorithmes d'apprentissage machine par le biais de modifications stratégiques des données – ce qu'il appelle « l'action collective algorithmique ». Ses recherches ont révélé que des protections de la vie privée plus strictes entravent en réalité l'efficacité de l'action collective, créant des compromis complexes pour la politique de confidentialité.
Audit et apprentissage avancés
Les séances de l'après-midi ont exploré des solutions techniques sophistiquées. Olive Franzese-McLaughlin , chercheuse postdoctorale émérite chez Vector, a présenté une méthode d'audit d'apprentissage automatique cryptographiquement sécurisée utilisant des schémas d'engagement et des preuves à divulgation nulle de connaissances, permettant ainsi des audits sans fuite d'informations sensibles. David Emerson , spécialiste en apprentissage automatique appliqué chez Vector, a présenté des contraintes adaptatives d'espace latent pour l'apprentissage fédéré personnalisé, améliorant les méthodes de pointe comme Ditto grâce à l'intégration de contraintes tenant compte de la distribution.
D'autres exposés éclair ont couvert tous les sujets, de la convergence exponentielle dans la méthode de Monte Carlo de Langevin projetée ( Alireza Daeijavad, Université McMaster ) à l'échantillonnage privé localement optimal ( Hrad Ghoukasian, Université McMaster ), illustrant la profondeur théorique du domaine.
Impératifs stratégiques : quelles sont les prochaines étapes ?
Le message principal de l'atelier était clair : à mesure que les capacités de l'IA progressent rapidement, notre capacité à garantir que ces systèmes restent sécuritaires, respectueux de la vie privée et conformes aux valeurs humaines devient de plus en plus cruciale.
Les principales priorités qui ressortent de la recherche sont les suivantes :
- Élaboration de garanties prouvables : Passer des méthodes heuristiques aux systèmes dotés de garanties mathématiques, notamment pour le désapprentissage automatique et la protection de la vie privée
- Intégrité de l'évaluation : Créer des cadres d'évaluation que les systèmes d'IA sophistiqués ne peuvent ni manipuler ni contourner.
- Protection de la vie privée de bout en bout : concevoir des systèmes où la protection de la vie privée s’étend à l’ensemble des pipelines d’apprentissage automatique, et pas seulement à l’entraînement du modèle final.
- Préparation à l'action collective : Comprendre et atténuer les tentatives coordonnées d'influence sur les systèmes d'IA
- Pont entre l'industrie et le monde universitaire : Transformer les technologies de pointe en matière de protection de la vie privée en outils pratiques que les organisations peuvent réellement déployer.
La voie à suivre exige une collaboration continue entre le milieu universitaire et l'industrie, des méthodes d'évaluation rigoureuses et, surtout peut-être, une humilité face aux défis qui nous attendent dans la construction de systèmes d'IA toujours plus puissants.
Comme l'ont démontré ces chercheurs, relever les défis liés à la sécurité et à la confidentialité de l'apprentissage machine exige à la fois des avancées théoriques et des solutions pratiques. L'atelier a souligné que, malgré des progrès significatifs, la poursuite de la collaboration entre le milieu universitaire et l'industrie sera essentielle à mesure que les systèmes d'IA se généralisent dans la société.

Vous en voulez plus ?
Notre communauté de recherche de renommée internationale fait des percées majeures dans la science et l'application de l'IA.










































































































