Les applications du monde réel nécessitent des systèmes d'IA capables de traiter et de raisonner à partir de divers types d'informations (images, textes et sons), à l'instar de la perception humaine et de l'interaction avec le monde. Par exemple, dans le domaine des soins de santé, l'IA multimodale peut analyser les images médicales et les dossiers des patients pour aider au diagnostic et à la planification du traitement. Cette capacité à comprendre et à intégrer différents types d'informations est fondamentale pour libérer le potentiel de l'IA dans de nombreux scénarios du monde réel.
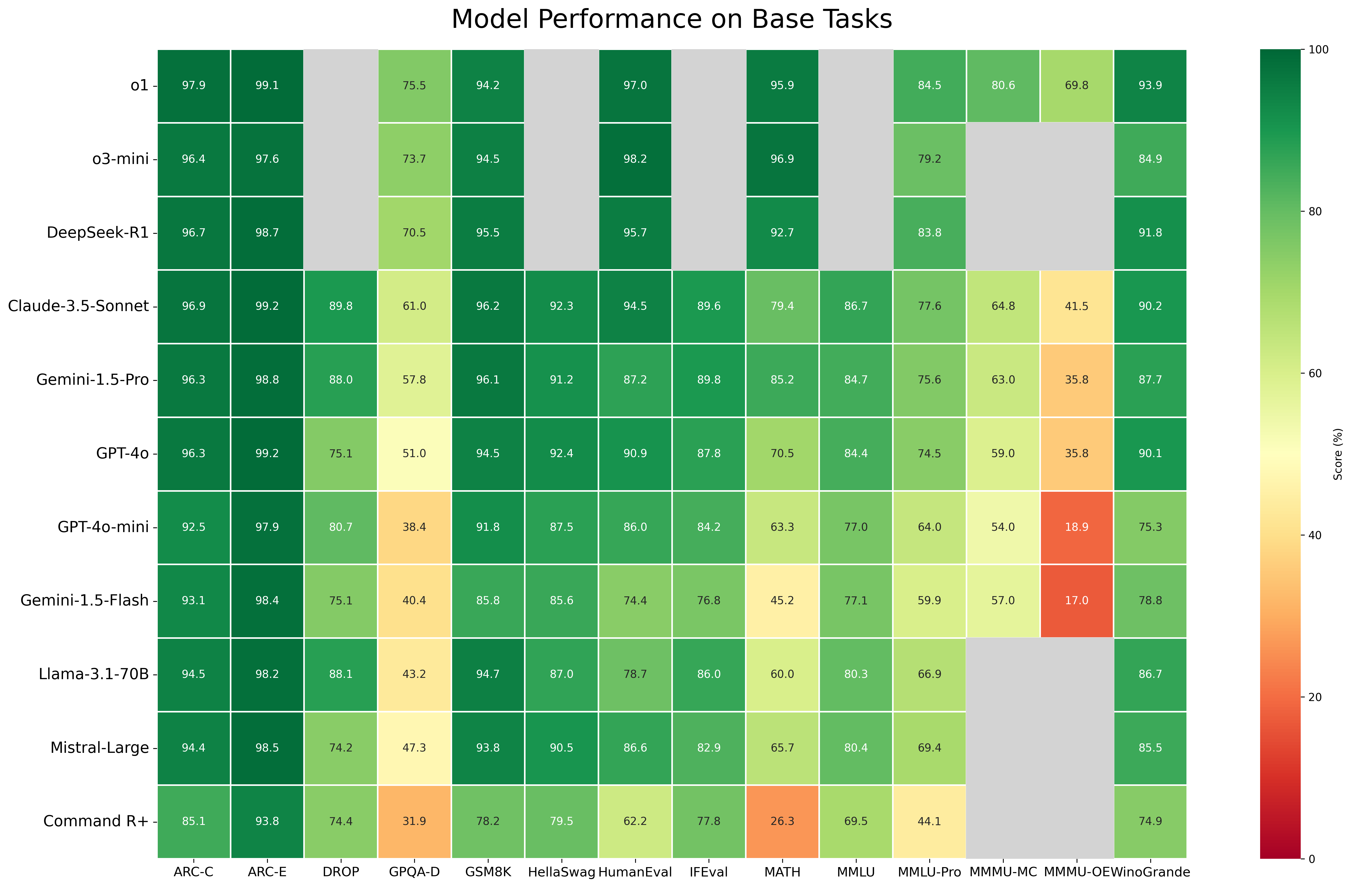
Le benchmark Multimodal Massive Multitask Understanding (MMMU), développé par Wenhu Chen, membre de la faculté Vector et titulaire de la chaire CIFAR AI au Canada, évalue la capacité d'un modèle à utiliser le raisonnement pour des problèmes nécessitant l'interprétation d'images et de textes dans des formats de questions à choix multiples et de questions ouvertes. Les questions sont stratifiées en fonction de la difficulté du sujet (facile, moyen, difficile) et du domaine, notamment les mathématiques, la finance, la musique et l'histoire.
Lors de l'évaluation, o1 a fait preuve d'une compréhension multimodale supérieure pour différents formats de questions et niveaux de difficulté, tout comme Claude 3.5 Sonnet, mais dans une moindre mesure. La plupart des modèles ont connu une baisse significative de leurs performances lorsqu'ils ont été confrontés à des questions multimodales ouvertes plus difficiles. Cette tendance s'est vérifiée à tous les niveaux de difficulté. o1 a présenté le profil le plus résistant, dans la mesure où la baisse a été beaucoup moins importante. Claude-3.5-Sonnet a maintenu des performances relativement stables, mais seulement à un niveau de difficulté moyen. Les performances ont également baissé de manière générale avec l'augmentation de la difficulté des questions pour tous les modèles.
Ces résultats indiquent que si l'IA multimodale progresse, le raisonnement ouvert et les tâches multimodales complexes restent des défis importants, mettant en évidence les domaines de recherche et de développement futurs.