Il s'agit d'une fenêtre de navigation qui se superpose au contenu principal de la page. En appuyant sur le "X" dans le coin supérieur droit de la fenêtre modale, vous la fermerez et reviendrez à l'endroit où vous étiez sur la page.
Voir les articles sur
Il s'agit d'une fenêtre d'appel à l'action qui se superpose au contenu principal de la page. En appuyant sur le "X" dans le coin supérieur droit de la fenêtre modale, vous la fermerez et reviendrez à l'endroit où vous étiez sur la page.
Collaborons à l'adresse
Il s'agit d'une fenêtre de recherche qui se superpose au contenu principal de la page. En appuyant sur le "X" dans le coin supérieur droit de la fenêtre modale, vous la fermerez et reviendrez à l'endroit où vous étiez sur la page.
Le chercheur Bo Wang, spécialiste des vecteurs, met au point une méthode d'harmonisation des données médicales provenant de plusieurs hôpitaux
9 mars 2020
2020IA générativeSantéPerspectivesApprentissage automatiqueLa rechercheRecherche 2020L'IA digne de confiance
Par Ian Gormely
Les données sont le carburant qui permet aux algorithmes d'intelligence artificielle de fonctionner. Mais il n'est pas toujours facile d'obtenir de bonnes données utilisables. C'est un problème que Bo Wang, membre de la faculté Vector, ne connaît que trop bien.
Afin de constituer un ensemble de données médicales (telles que des images médicales ou des notes cliniques) suffisamment important pour permettre à un modèle d'apprentissage automatique de fonctionner, les chercheurs comme Wang doivent souvent combiner des données provenant de plusieurs hôpitaux. Plus précisément, Wang souhaitait appliquer aux images cardiaques le modèle de classification des images de cancer recueillies auprès d'un groupe d'hôpitaux. Mais les données collectées par les hôpitaux, ainsi que la manière dont elles sont collectées et triées, tendent à varier d'un hôpital à l'autre, voire d'un service à l'autre. Les harmoniser serait une tâche difficile et fastidieuse. Il devait y avoir un meilleur moyen.
Il existait déjà des méthodes permettant de cibler l'adaptation d'un domaine à une source unique, c'est-à-dire de transférer le modèle d'un hôpital à un autre. Mais cela "néglige les scénarios plus pratiques dans lesquels les données de formation proviennent de sources multiples", dit-il. Il s'est interrogé : "Pouvons-nous forcer le modèle à être généralisable à différents domaines ?"
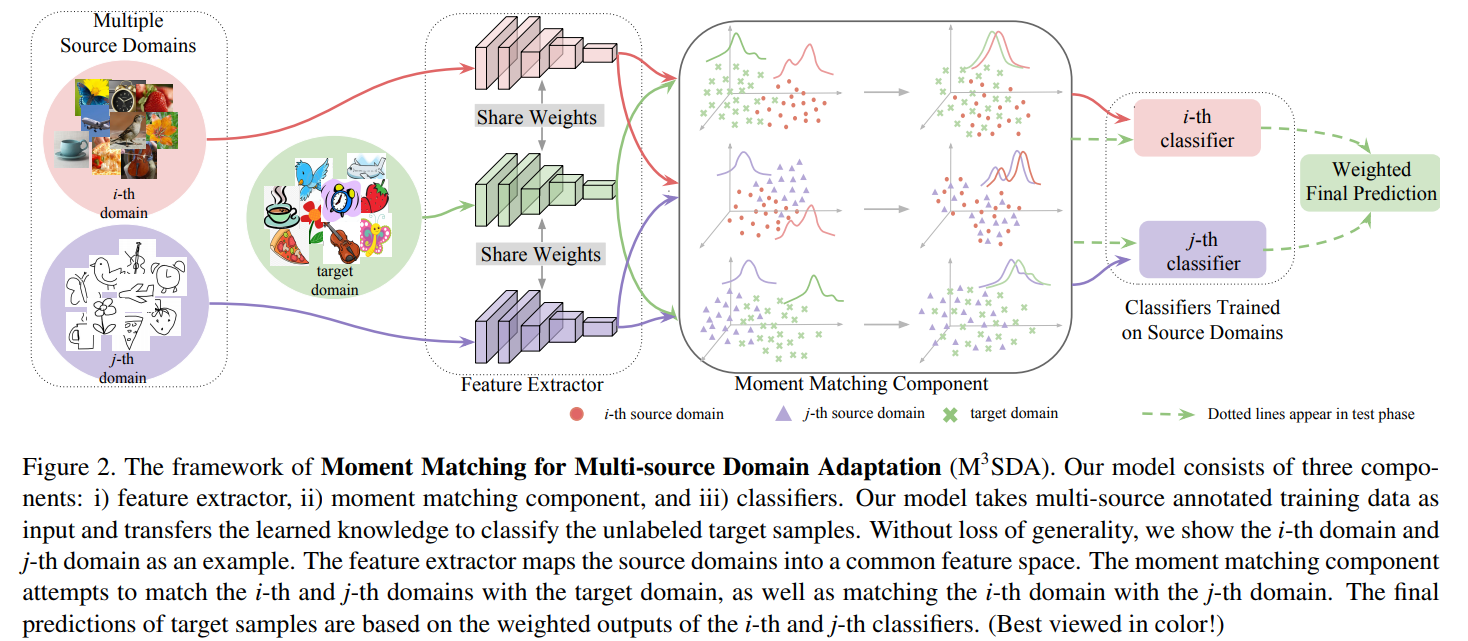
"Moment Matching for Multi-source Domain Adaption", coécrit par Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang et Kate Saenko, et publié dans Proceedings of the IEEE International Conference on Computer Vision en 2019, suggère que oui, ils peuvent très bien le faire. En fait, leur modèle - qu'ils abrègent sous le nom de M3SDA - offre non seulement un moyen de rassembler des informations provenant de plusieurs sources en une seule, mais il annote également des images internet non étiquetées, ce qui permet d'obtenir un ensemble de données de 600 000 images réparties dans 345 catégories différentes. "Je pense qu'il s'agit de la plus grande collection d'adaptation de domaine multi-ensembles", déclare Wang.
Et il a déjà un impact. Lauren Erdman, étudiante en doctorat chez Vector et à l'hôpital SickKids, sous la supervision d'Anna Goldenberg, membre du corps professoral de Vector, est tombée sur l'article alors qu'elle procédait à une analyse documentaire. "J'ai tout de suite su qu'il me serait utile dans mon travail", dit-elle en qualifiant l'approche de Wang de "distincte" des autres. Erdman utilise actuellement l'algorithme de Wang dans deux études. La première utilise M3SDA pour harmoniser les différences entre les données créées par les échographes. L'autre étudie l'algorithme - le résultat est une courbe à valeur continue et l'alignement est proportionnel à la similarité des courbes - pour cartographier le son de l'écoulement de l'urine afin d'étudier sa vitesse, son volume et sa durée.
"Nous avons mis au point une approche très simple qui permet d'obtenir de meilleurs résultats", explique M. Wang, qui précise que son équipe et lui ont testé le modèle dans le domaine de la vision par ordinateur, mais qu'ils y voient également un "énorme potentiel" pour les applications médicales, en particulier l'analyse d'images médicales. "La plupart des projets actuels d'analyse d'images médicales souffrent d'un manque d'images annotées et du fait que les modèles formés sur les données d'un hôpital ne peuvent pas être directement appliqués aux images d'un autre hôpital. Notre méthode a le potentiel de surmonter ces deux limitations en même temps".
En rapport :
2025
Écosystème de l'IA
Perspectives
L'écosystème de l'IA en Ontario : une croissance économique réelle grâce à un nombre record d'emplois et d'investissements privés
2025
ANDERS
Santé
Recherche
Recherche 2025
Transformer le soutien à la santé mentale des jeunes : Le modèle de réponse à la crise du FAIIR alimenté par l'IA
2025
Recherche
Recherche 2025
Percée de l'IA dans les prévisions météorologiques : comment l'innovation canadienne transforme les prévisions climatiques | Aardvark Weather
Nous utilisons des cookies pour nous assurer que vous bénéficiez de la meilleure expérience possible sur notre site web. Si vous continuez à utiliser ce site, nous supposerons que vous en êtes satisfait.OkNonPolitique de confidentialité