
By David Emerson
Introduction
With the recent emergence of high-performing, general-purpose large language models (LLMs), such as ChatGPT and LLaMA, there has been a rapid expansion of both research and public interest in the capabilities and application of such LMs. As an increasing amount of resources is focused on advancing the frontiers of natural language processing (NLP), and LLMs in particular, keeping up with these changes has become challenging. In this post, we provide a discussion of some recent trends in LLMs and techniques for applying them to downstream tasks, through prompt engineering. We’ll also discuss new methods for improving their performance above and beyond the traditional framework of full-model fine-tuning. Such approaches include instruction fine-tuning and parameter efficient fine-tuning. The goal is to reach a better understanding of how LLMs are trained and how they can be leveraged to solve real-world problems.
Language Models are Getting Bigger and Training for Longer
Over the past few years, two important trends have developed with respect to LM architectures and training, bolstered by many different breakthroughs and significant engineering efforts. Both of these trends are present in the scaling diagram shown in Figure 1. While some of the models in the figure are encoder-only style models, such as BERT and RoBERTa, the majority of contemporary LLMs are generative encoder-decoder or decoder-only transformer models. Therefore, those architectures will be the main focus of the discussion to follow.
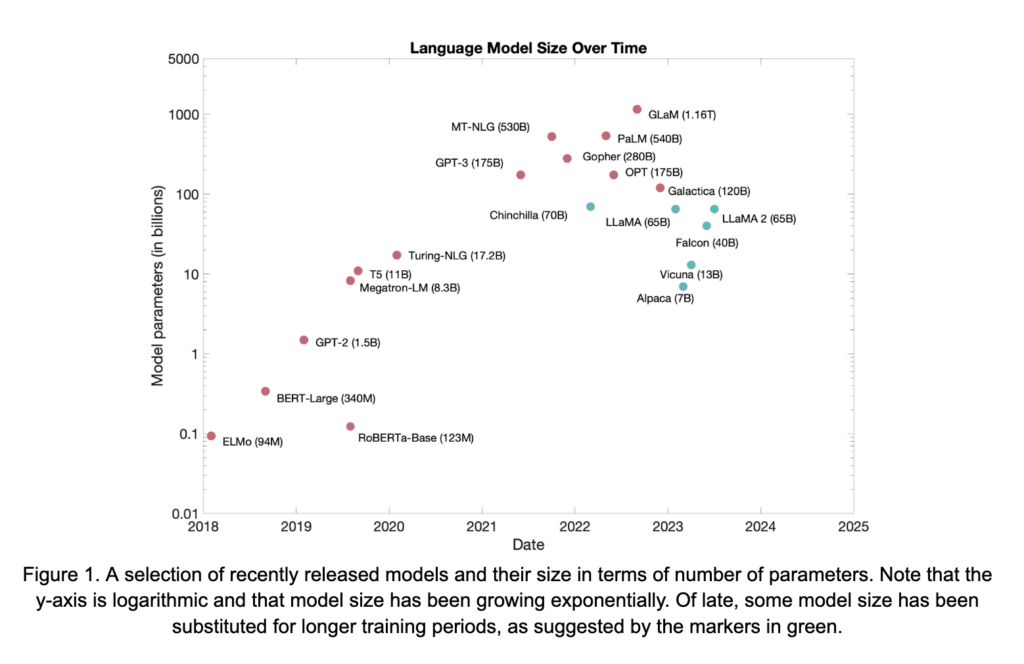
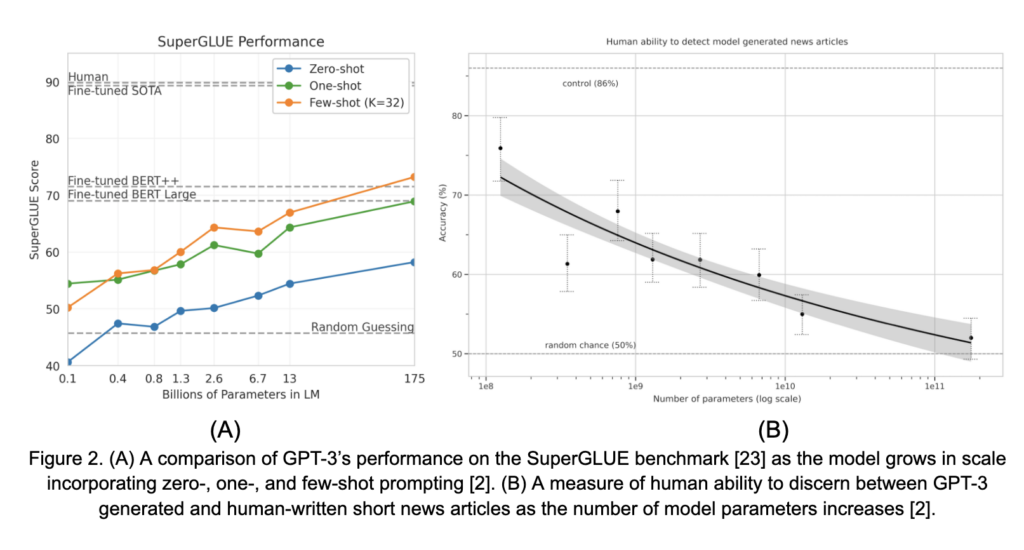
The first trend evident in Figure 1 is that LLMs have been growing rapidly over time. Scaling of these models has been facilitated in many ways, including better pre-training techniques, larger pre-training corpora, and advances in hardware and distributed training methods, among many others. However, this increase in model size is not simply for scaling purposes. The capabilities of these models, especially their zero- and few-shot abilities (discussed in detail below), grow significantly with scale. This was poignantly highlighted in [2]. Two results from that work are shown in Figure 2. In Figure 2A, the performance of GPT-3 on the SuperGLUE benchmark, in zero- and few-shot settings, grows smoothly with model size. Similarly, in Figure 2B, human ability to discern between GPT-3-generated short news articles versus those written by humans decreases steadily towards random chance as the model scales in size. These observations, and others, have driven significant interest in LM scale as a means of achieving general NLP task abilities.
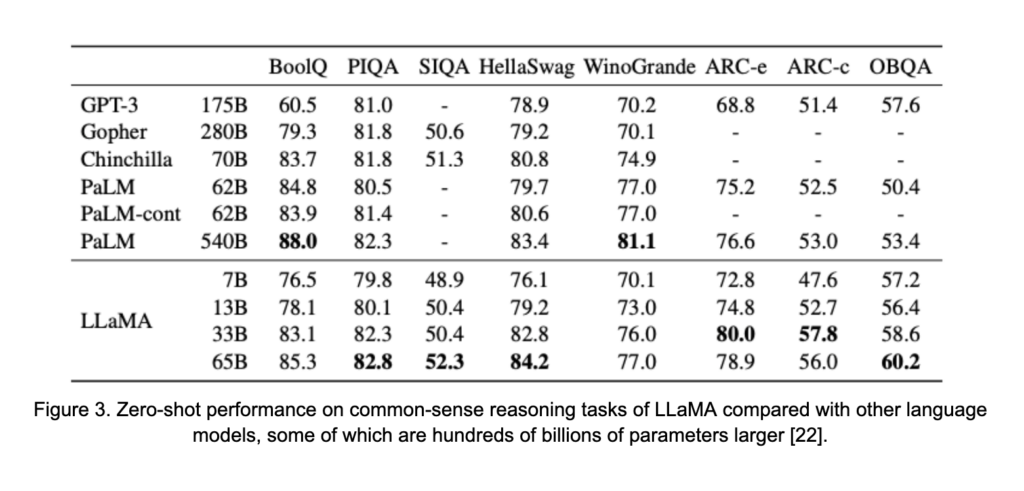
The second theme emerging in LLMs is more subtly present in Figure 1. On the right-hand side, highlighted in green, is a number of recently released, high-performing models. While these models remain quite large, in the tens of billions of parameters, they do not necessarily follow the scaling trend that might be inferred from the models in red. The models are trading some size in exchange for larger pre-training datasets and longer pre-training phases. This shift is motivated by the study in [8], which suggested that, despite the already significant resources used to train many LLMs, previous models are under-trained relative to their size. This, for example, led to the training framework of LLaMA [22], which saw 1.4 trillion tokens during training. This total is a large jump from the 300 billion tokens seen by OPT-175B [29], a much larger model, during its pre-training phase. The results are shown in Figure 3. In spite of its smaller size, LLaMA outperforms models with up to 0.5 trillion parameters.
Prompting: Motivation, Benefits, and Construction
Formally, prompting is the process of using carefully crafted phrases or templates to construct input text that conditions a pre-trained LM to accomplish a downstream task. We have already seen, in Figures 2A and B, that prompted LLMs are capable of performing tasks with a surprising degree of accuracy without requiring fine-tuning. Before discussing this further, consider the following example prompt template and the associated completed prompt for the BoolQ task, taken from [2].
![Figure showing the prompt template used for reading comprehension tasks alongside a filled example. The left side displays the abstract template structure: the input begins with a title placeholder and a passage placeholder, followed by the word 'question:' in purple and a question placeholder and 'answer:' in green with the token [X] indicating where the model's response is expected. The right side shows a concrete example: the passage reads 'Rabies transmission – Transmission between humans is extremely rare, although it can happen through organ transplants or through bites.' The question shown in purple is 'can a person transmit rabies to another person?' with the answer field left blank, indicating this is the prediction target.](https://vectorinstitute.ai/wp-content/uploads/2023/10/Screenshot-2023-10-20-at-11.13.08-AM-1024x175.png)
On the left is an example of a prompt template. Each component in angled brackets is filled with information from the task we are hoping to accomplish. The lavender text is a structure that has been created to present the model with the requisite information clearly. Finally, the goal is to have the model generate text in place of the navy “X” with the correct answer to the question. On the right is an example of the filled template for a question, with context, from the BoolQ dataset.
Zero- and Few-shot Prompting
The prompt above is known as a “zero-shot” prompt. It does not include any “labeled” examples, also termed demonstrations or shots, as part of the input to the LM. Few-shot prompts provide labeled examples as part of the prompt template with the goal of providing additional task-specific guidance to the LM. Examples of one-shot and few-shot prompts for a sentiment classification task are below.

There are several advantages to including demonstrations within prompts. Foremost among them is that downstream task performance is often improved, as shown in Figure 2. The gap between zero- and few-shot prompting often widens with model scale. In addition, the inclusion of labeled examples strongly encourages the model to respond in a way that makes mapping the generated text to a label easier, which is a common challenge with prompting. Consider the sentiment analysis task above. The label space for the task is “positive” and “negative.” However, the model, left to its own devices, might instead respond with “enjoyable” or “disappointing,” complicating the process of programmatically determining the predicted label. Including examples helps the model respond in the way that we expect.
The way in which LMs incorporate demonstrations into the predictive process is nuanced. Several studies have shown that the quality, distribution, and even order of demonstrations provided have a strong and sometimes unpredictable impact on a model’s ability to perform a downstream task [17,18,26]. To this end, some research has considered strategies for selecting optimal demonstrations to be included in a prompt to maximize downstream task performance over simple random selection and ordering [1,15].
While few-shot prompting is quite effective, there are several drawbacks to keep in mind. First, the demonstrations consume valuable space in the LMs’ input capacity (also known as its context). Generally, transformers are capable of consuming a fixed number of tokens to condition the generation process. For example, LLaMA has a fixed context length of 2048 tokens. While this sounds like a lot of tokens, injecting multiple demonstrations quickly adds up, especially for a task such as document summarization where each demonstration might incorporate a large chunk of text. This limits the number of examples that may be included in prompts. More importantly, large contexts incur high computation costs and slow down inference. This is because, for example, attention in transformers is an operation, where
is the number of tokens in the context.
Another disadvantage is that labeled data may be private. In [6], membership-inference attacks were successfully designed to reveal labeled data used in few-shot prompts. While that work also proposed an approach to protect such data, inclusion of sensitive data in prompts remains a risk. Finally, several works have shown that, for certain tasks, few-shot prompting is not enough to elicit good performance from an LM [12,25]. This has motivated significant research into Chain-of-Thought prompting, which will be discussed in detail in a subsequent blog post.
![Table 1 showing validation F1 scores for a BART-based Named Entity Recognition task after full-model tuning across four different prompt templates. The table has three columns: Positive Template, Negative Template (labelled 'sic') and Validation F1 score. Row 1: Positive – '⟨text⟩ ⟨candidate⟩ is a [X] entity'; Negative – '⟨text⟩ ⟨candidate⟩ is not a named entity'; Val. F1: 95.27. Row 2: Positive – '⟨text⟩ The entity type of ⟨candidate⟩ is [X]'; Negative – '⟨text⟩ The entity type of ⟨candidate⟩ is none entity'; Val. F1: 95.15. Row 3: Positive – '⟨text⟩ ⟨candidate⟩ belongs to [X] category'; Negative – '⟨text⟩ ⟨candidate⟩ belongs to none category'; Val. F1: 88.42. Row 4: Positive – '⟨text⟩ ⟨candidate⟩ should be tagged as [X]'; Negative – '⟨text⟩ ⟨candidate⟩ should tagged as none entity'; Val. F1: 76.80. The token [X] appears highlighted in the positive templates, indicating the model's prediction target. The top two templates achieve the highest scores, both above 95.](https://vectorinstitute.ai/wp-content/uploads/2023/10/Fig-6-1024x238.png)
How You Ask Matters
For most downstream tasks, the goal of a prompt is to maximize the LMs’ ability to perform that task with little to no need for labeled data. However, even the best performing LMs are sensitive to the structure of the prompt provided. How you ask the model to perform the target task matters, and sometimes it is even the determining factor that ensures the completion of the task altogether. Consider the examples detailed in Table 1 from [4]. Each row in the table corresponds to a potential template design for a named-entity recognition task. There is a large difference in performance between a model using the best performing prompt (top row) and the worst (bottom row). This difference is even more stark when considering that the model is actually fine-tuned for this task using these prompt structures. The sensitivity of LMs to prompt structure is well-documented and implies that thoughtful prompt design can have a large impact on model performance.
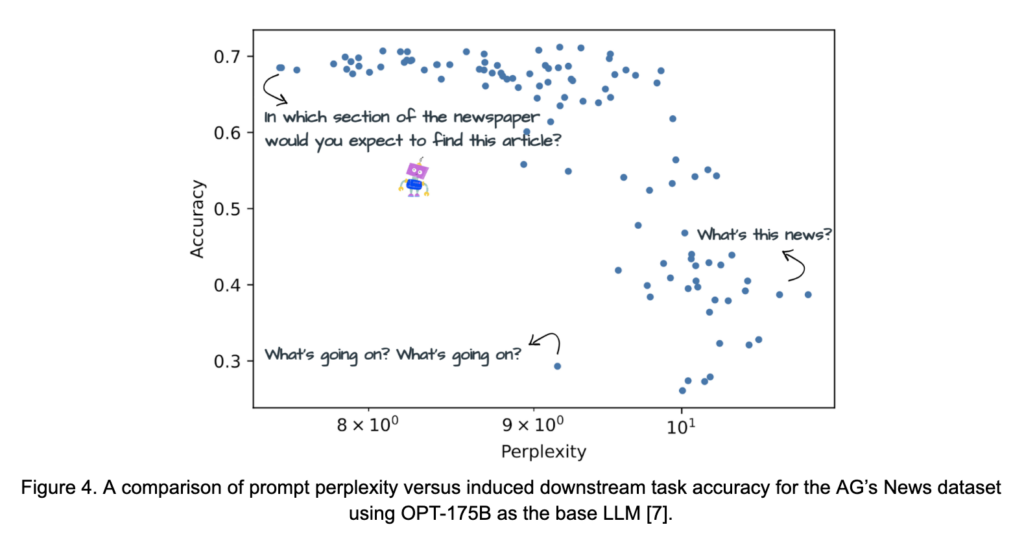
With this in mind, a number of studies have considered the question of: “what makes a prompt a good prompt?” The question is a complicated one, as certain types of prompts are better suited for certain types of models. For example, the authors of OPT observed that the model did not respond well to “declarative instructions or point-blank interrogatives [29].” The same is not necessarily true for instruction-fine-tuned models, discussed below, such as Vicuna [3]. Nevertheless, several studies have highlighted some principles that are useful to keep in mind when constructing prompts. In [7], the relationship between a prompt’s effectiveness and its perplexity – a proximal measure of a prompt’s fluency and simplicity from the LMs perspective – is investigated. This relationship is displayed for prompts meant to classify news articles into categories in Figure 4. The work empirically suggests that prompts which are straightforward, fluent, and task-specific perform best. Another set of studies in [19] compiled a set of prompt design suggestions based on experimentation with the GPT family of LMs. These include:
- Using low-level patterns rather than sophisticated concepts that require background to understand
- Breaking down complex tasks into multiple simpler tasks when possible
- Providing expected outputs and constraints and turning negated statements into assertion statements
While these recommendations help to focus exploration and design of optimal prompts, it is important to recognize that experimentation with prompt construction is often required to evoke optimal performance from an LM on a particular task.
Discrete Prompt Optimization
Because the manual design of prompts can be challenging and also critical to the successful completion of a downstream task, a significant amount of research has aimed to improve the search process through various optimization procedures. The most straightforward of these approaches focus on generating a diverse pool of prompts over which performance may be assessed. Examples include prompt mining [10], where phrasing and common text is scraped from large text corpora to construct diverse prompts, and prompt paraphrasing [7,10,28], in which a large variety of prompts is created from “seed” prompts through round-trip translation, thesaurus replacement, or paraphrase models. Each of these methods aims to expand on human-designed prompts in order to evaluate a larger candidate pool. A sophisticated variant of these approaches is GrIPS [20], which combines these approaches, along with several text editing schemes, to iteratively search for optimal prompt designs.
An interesting optimization approach, known as AutoPrompt, is proposed in [21]. The approach searches for a set of “trigger” tokens of the form
![A mathematical expression defining the structure of a prompt template for masked language model tasks. The formula reads: x-subscript-prompt equals ⟨text⟩ [t₁] … [tₙ] [MASK], followed by a period. In the formula, x-subscript-prompt is rendered in bold to denote the full prompt input; ⟨text⟩ represents the input text placeholder; [t₁] through [tₙ] represent a sequence of n learnable prompt tokens; and [MASK] is the masked token position where the language model is expected to generate a prediction. All placeholder and token elements are rendered in blue.](https://lh3.googleusercontent.com/P0qoz6LYh9DgKwTD4p61Tv90xYDXZA5VNeTbw9avd7GeEU8w8ygI4ZU5huNQmy2DiQRERU-oc1dOEUwOY9te-OgrAIuDUefSrAauQktLbNSNfllqvD-QYY5XWwKIQaObWuRsAbB1ncvOxdIuhE-pWbA)
Let represent the vocabulary of the LM under consideration. For a label
and associated portion of the vocabulary, prompts are scored as
![Equation 3.1 defining the probability of a label given a prompt in a masked language model setting. The equation reads: P of y given x-subscript-prompt equals the sum over all w belonging to V-subscript-y of P of [MASK] equals w given x-subscript-prompt. In this expression, y is the predicted label, x-subscript-prompt is the structured prompt input, V-subscript-y is the vocabulary of words associated with label y, w is a candidate word from that vocabulary and [MASK] is the masked token position the model is asked to fill. The equation defines the label probability as the aggregated probability mass the model assigns to all vocabulary terms associated with that label at the mask position.](https://lh4.googleusercontent.com/y5qQNipO2_sAjdITH2piAlCFufxPH27fXxlWxq5iFgrqo46OQPXQG-rA9v-pSFG__XPIMjoiJoswsDnHNwmLvHLda4rKg4HBpBfPuVtDitT5rG_jNX4N_uNxMGvbSECFqS1ASOKNeljtVSv95xOp4Ck)
At each iteration, a token, , with embedding
is selected for modification. We search for
, with embedding
, with greatest potential to increase label probability, as expressed in Equation (3.1),
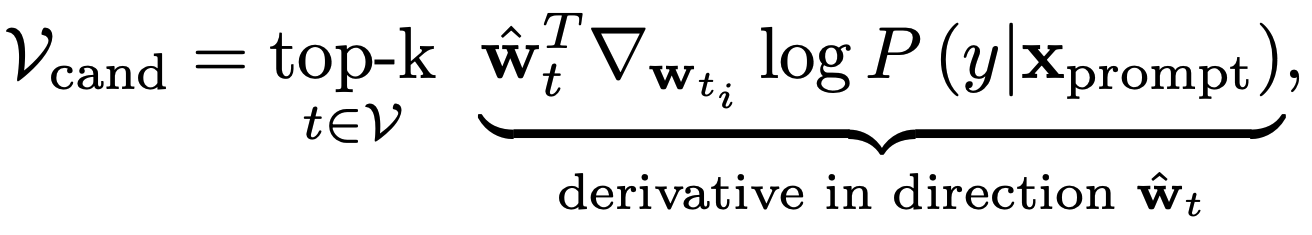
where is the number of candidate replacement tokens to be considered. Modifying the
-th prompt token with
to form
, we select the
that maximizes the label probabilities over an independently drawn training batch
as
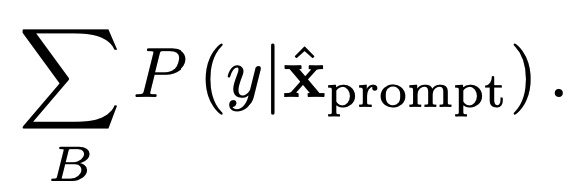
This approach can be very productive at increasing prompt effectiveness, as seen in Table 2. Accuracy induced by manual prompts of BERT and RoBERTa models for the SST-2 sentiment are improved by 19.1% and 6.2%, respectively. While these improvements are quite large, there are some downsides to this approach. The first is that the method requires calculation of a gradient with respect to the model’s vocabulary embeddings. While no parameters are updated in this process, calculation of the gradient for LLMs, even for a small subset of the parameters, can be quite resource-intensive. In addition, the prompts resulting from this token-based optimization approach are often difficult to read and tend to bear little resemblance to prompts that a human might construct. This is highlighted in Table 3. Some current research aims to address this issue, which, in general, plagues many other discrete prompt optimization approaches such as RLPrompt [5]. However, it is still an area of active investigation.
![Two tables presented together. Table 2 shows performance on the SST-2 sentiment classification task comparing manual and AutoPrompt-generated prompts across four model configurations. The table has three columns: Model, Dev. Acc. and Test Acc. Row 1: BERT (manual prompt) – 63.2 / 63.2. Row 2: BERT (AutoPrompt) – 80.9 / 82.3. Row 3: RoBERTa (manual prompt) – 85.3 / 85.2. Row 4: RoBERTa (AutoPrompt) – 91.2 / 91.4. AutoPrompt consistently outperforms manual prompts for both models, with RoBERTa (AutoPrompt) achieving the highest scores overall. Table 3 shows three tasks with their associated prompt templates and the optimal prompts discovered by AutoPrompt. Columns are: Task, Template and Prompt found by AutoPrompt. Row 1: Sentiment Analysis – template '⟨text⟩ [t₁] … [tₙ] [MASK]' – prompt 'unflinchingly bleak and desperate Writing academicswhere overseas will appear [X]'. Row 2: NLI – template '⟨premise⟩ [MASK] [t₁] … [tₙ] (hypothesis)' – prompt 'Two dogs are wrestling and hugging [X] concretepathic workplace There is no dog wrestling and hugging'. Row 3: Fact Retrieval – template '⟨subject⟩ [t₁] … [tₙ] [MASK]' – prompt 'Hall Overton fireplacemade antique son alto [X]'. In the AutoPrompt column, the optimized prompt tokens are highlighted in lavender. The caption notes that while these prompts perform well on their respective metrics, they are difficult to interpret or understand semantically.](https://vectorinstitute.ai/wp-content/uploads/2023/10/Screenshot-2023-10-20-at-11.19.46-AM-1024x580.png)
IFT and PEFT
Prompting has a number of important advantages. Through prompting, LLMs demonstrate a striking ability to perform tasks for which they were never trained. Moreover, multi-task batching is easily achieved through prompting. That is, the same LLM can be used for many different tasks, even within the same batch, by simply modifying the prompt. Further, model interaction and inference is achieved purely through natural language, lowering the barriers to using the models. On the other hand, we know that task performance remains quite sensitive to prompt design. Moreover, the search for optimal prompts is challenging and often tedious. Finally, and possibly most importantly, for many tasks, a large gap remains between the performance of prompted LLMs and task-specific models trained to perform a single task with high fidelity. These downsides have motivated additional approaches to improving LLMs’ abilities to complete specific downstream tasks, while attempting to preserve as many of the advantages of the prompting approach as possible.
Instruction Fine-Tuning
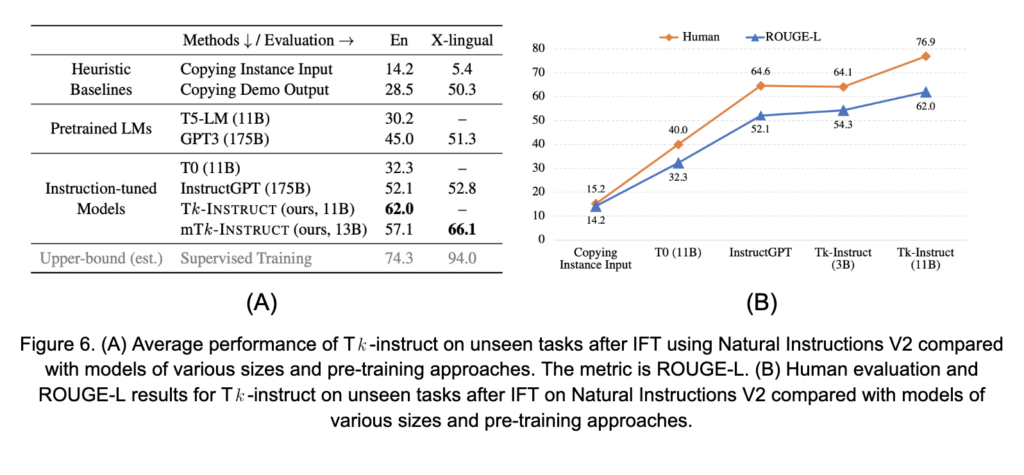
The observation that OPT does not respond well to “declarative instructions or point-blank interrogatives,” which was briefly touched on above, is both a true statement about the LLM and a fact that makes prompting the model to perform downstream tasks more difficult. Direct instructions and straightforward questions are often a natural way someone might start to interact with a generative LM. Instruction fine-tuning (IFT) aims to improve prompting performance while simultaneously making the process more intuitive. The basic idea is to provide a target LM with additional examples, beyond those seen during pre-training, with special structure. For IFT, this special structure comes in the form of instruction prompts coupled with a desired generated response across a wide variety of NLP tasks. Scale and quality of these datasets are important for the success of the IFT process. One such collection of data is the Natural Instruction V2 Dataset introduced by [24]. This dataset incorporates more than 1600 different tasks, from 76 different task categories, each paired with an instruction-based prompt. An illustration of the different tasks and their relative representation in the dataset is shown in Figure 5.

For IFT, the target LM is further fine-tuned (also known as meta-tuning) on text drawn from the IFT dataset. The downside of this approach is that it requires computational resources equivalent to full-model fine-tuning, albeit for a much shorter period of time than the pre-training cycles of most LLMs. On the other hand, the approach has been shown to improve an LM’s ability to incorporate prompts and perform downstream tasks as instructed. See, for example, the results from [24] shown in Figures 6A and B. IFT preserves many of the benefits of prompting while aiming to improve the effectiveness of prompting for the target models. The major disadvantages are that IFT is still essentially fine-tuning, requires careful stopping criteria to avoid losing the model’s general capabilities (catastrophic forgetting), and does not necessarily close the “state-of-the-art” gap with task specific fine-tuning.
Parameter Efficient Fine-Tuning
Full-model fine-tuning of LLMs is often rendered completely infeasible due to the massive computational resources required to carry out the training, even for short periods of time [27]. Moreover, even with the resources to produce a task-specific version of an LLM, it is likely that a separate model needs to be fine-tuned for each distinct task, necessitating duplication of storage, compute, and hosting infrastructure to actually put those models to use. Therefore, alternative approaches to closing the aforementioned gap in prompted LLM performance have been sought.
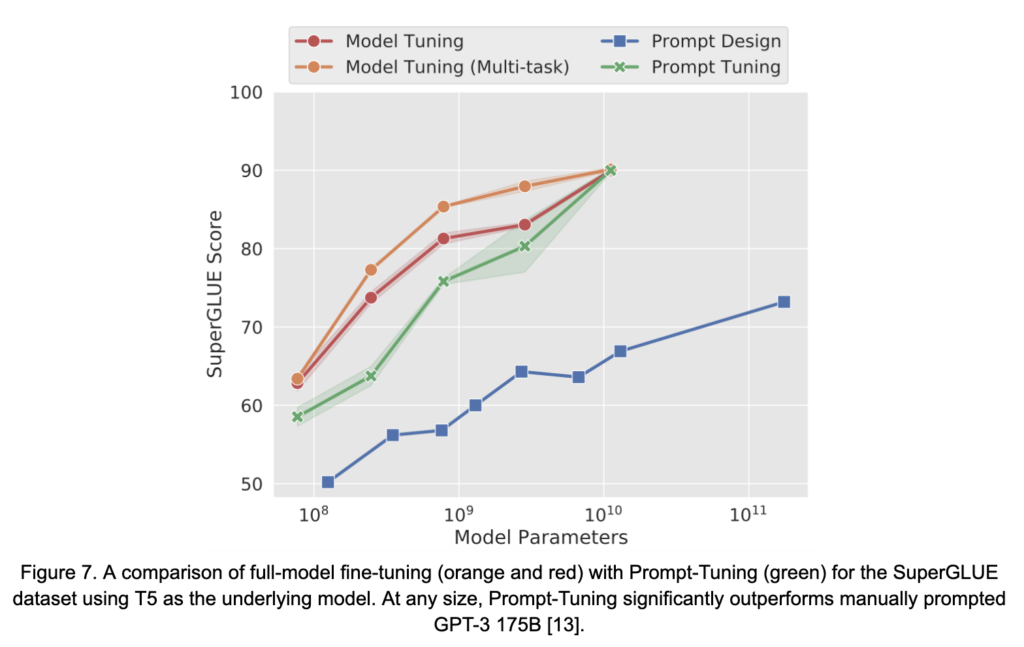
A natural extension of discrete prompt optimization is relaxation of the search space from discrete tokens to the continuous space of token embeddings through manipulation or augmentation of the embedding layer of the LMs. These methods are known as continuous prompt optimization techniques and include methods such as Prompt-Tuning [13] and Prefix-Tuning [14], and P-Tuning [16], among others. These methods are a subcategory of parameter-efficient fine-tuning (PEFT). PEFT methods train a small fraction of the overall model parameters while aiming to recover the accuracy achieved through full-model fine-tuning. Continuous prompt optimization approaches focus on modifying or augmenting model parameters in a way that coincides with or mimics the injection natural language prompts. Through this technique, the approaches have been shown to rival the performance of full-model fine-tuning across a number of NLP tasks, especially as the size of the underlying LM grows, see Figure 7 from [13]. The methods achieve multi-task batching by ensuring that the appropriate, task-specific, “prompt-associated” weights accompany each example in the batch during inference. However, interpretability of the learned “prompts” remains an issue and open question [11].
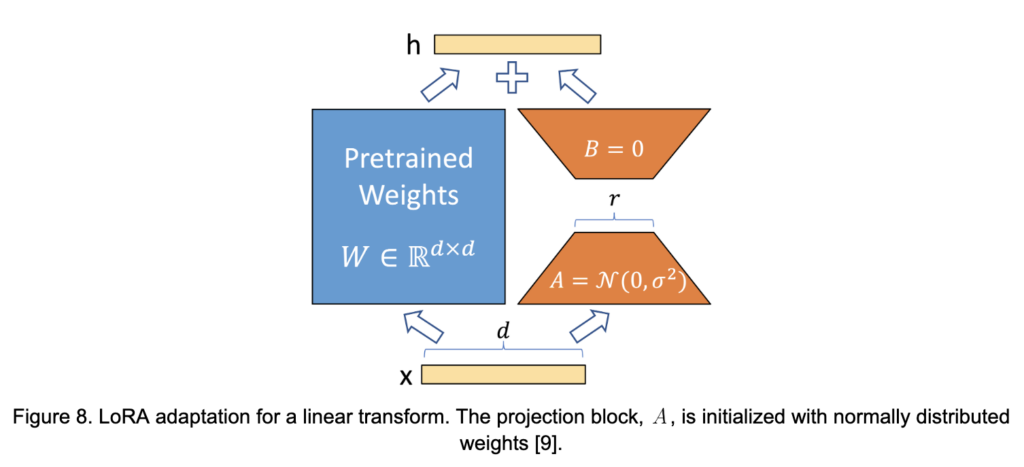
While continuous prompt optimization approaches have many advantages, the current state-of-the-art approach to PEFT is Low-Rank Adaptation (LoRA) [9]. LoRA generalizes LM adaptation beyond prompting, but still focuses on modification of the transformer attention mechanism, as is done in P-Tuning, for example. The idea is based on empirical observations that LLM weights are of low “intrinsic rank.” That is, while the tensors of LMs are high-dimensional, the information encoded in them actually tends to be well-approximated in a much lower dimension. This manifests itself, for example, in a precipitous drop-off of the singular values associated with a singular-value decomposition of the model weights.
Consider a weight matrix . The underlying hypothesis of LoRA is that, if
is of low “intrinsic rank,” then fine-tuning updates might also be. During training, LoRA freezes the original weights,
and constrains the updates to low-rank matrices
of the form
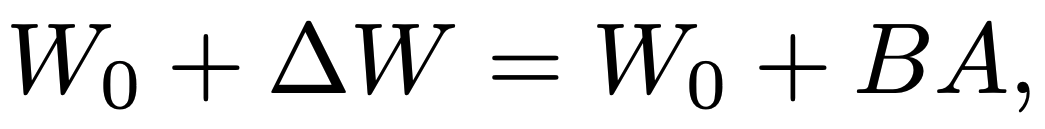
where and
and
is a small integer. If training updates are approximately low-rank, the weights in
and
should closely approximate the true update. This is illustrated in Figure 8.
There are four consequential matrices in multi-headed attention ,
,
,
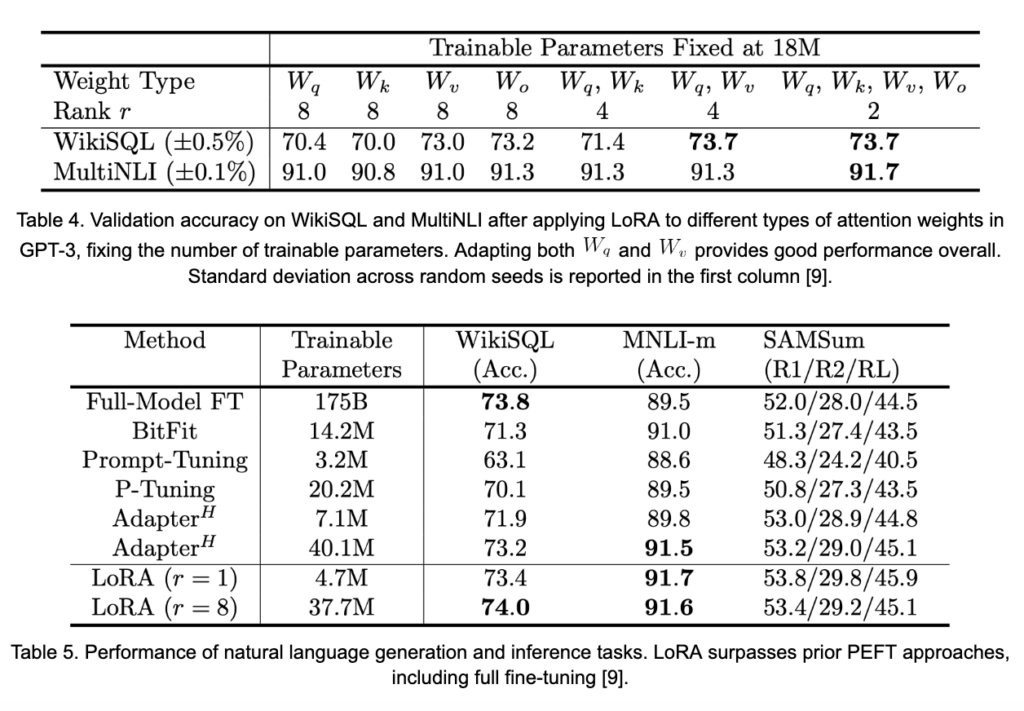
. An important question is: “which matrices should be adapted during training?” The results shown in Table 4 suggest that adapting at least both
and
provides a notable boost to performance. It is also significant to note that the magnitude of
can be very small, while still generating good performance. The smaller
is, the fewer weights are being trained. Adapting the attention matrices of
and
in each layer of GPT-3 with values for
of
and
, LoRA is able to capture and surpass full-model fine-tuning, as seen in Table 5.
Conducting multi-task batching with LoRA is a bit more complicated, compared to methods like Prompt-Tuning. Because LoRA essentially reparameterizes complete components of the model through the matrices and
, inputs associated with different tasks need to be routed through different LoRA matrices in order to produce the appropriate task-specific outputs. Such an approach is possible, but requires an elevated level of infrastructure orchestration. However, processing separate tasks in homogenous batches is simply a matter of applying the correct LoRA weights, which is still fairly flexible. Using LoRA for downstream tasks also moves further from the idea of interacting with the LMs through natural language, which increases the level of expertise required to engineer the completion of downstream tasks. However, the performance advantages of LoRA have made it an extremely popular approach to efficiently achieving high-accuracy for a variety of custom tasks through LLMs.
Conclusion
In this post, we have covered a large swathe of the current and emerging research on LLMs. These models continue to grow in size, train on increasingly large datasets, and see trillions of tokens during their pre-training phase. Prompting and prompt design continue to evolve as our understanding of best practices for engaging with LLMs through natural language becomes clearer and the capabilities of LLMs are explored. We have discussed state-of-the-art methods to automatically generate optimal prompts, both in the context of natural language and in the higher-dimensional spaces of the LLMs themselves. Finally, we considered two recent approaches to accomplish specific downstream tasks with higher fidelity. The first, IFT, aims to improve LLMs’ ability to perform tasks through direct prompting. The second, LoRA, is an extremely successful technique for fine-tuning a small fraction of an LLM’s total weights to perform a downstream task with similar accuracy to full-model fine-tuning, reducing the resources required to obtain state-of-the-art performance for a variety of tasks.
References
[1] S. Agrawal, C. Zhou, M. Lewis, L. Zettlemoyer, and M. Ghazvininejad. In-context examples selection for machine translation. In Findings of the Association for Computational Linguistics: ACL 2023, pages 8857–8873, Toronto, Canada, July 2023. Association for Computational Linguistics.
[2] T. Brown, B. Mann, N. Ryder, M. Subbiah, J.D. Kaplan, P. Dhariwal, A. Neelakantan, and et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020.
[3] W.-L. Chiang, Z. Li, Z. Lin, Y. Sheng, Z. Wu, H. Zhang, L. Zheng, S. Zhuang, Y. Zhuang, J. E. Gonzalez, et al. Vicuna: An open-source chatbot impressing GPT-4 with 90%* ChatGPT quality, March 2023.
[4] L. Cui, Y. Wu, J. Liu, S. Yang, and Y. Zhang. Template-based named entity recognition using BART. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 1835–1845, Online, August 2021. Association for Computational Linguistics.
[5] M. Deng, J. Wang, C.-P. Hsieh, Y. Wang, H. Guo, T. Shu, M. Song, E.P. Xing, and Z. Hu. RLPrompt: Optimizing discrete text prompts with reinforcement learning. In Conference on Empirical Methods in Natural Language Processing, 2022.
[6] H. Duan, A. Dziedzic, N. Papernot, and F. Boenisch. Flocks of stochastic parrots: Differentially private prompt learning for large language models. https://arxiv.org/abs/2305.15594, May 2023.
[7] H. Gonen, S. Iyer, T. Blevins, N. Smith, and L. Zettlemoyer. Demystifying prompts in language models via perplexity estimation. https://arxiv.org/abs/2212.04037, 12 2022.
[8] J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L.A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, J.W. Rae, O. Vinyals, and L. Sifre. Training compute-optimal large language models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 30016–30030. Curran Associates, Inc., 2022.
[9] E. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, L. Wang, and W. Chen. Lora: Low-rank adaptation of large language models, 2021.
[10] Z. Jiang, F.F. Xuand J. Araki, and G. Neubig. How can we know what language models know? Transactions of the Association for Computational Linguistics, 8:423–438, 2020.
[11] D. Khashabi, X. Lyu, S. Min, L. Qin, K. Richardson, S. Welleck, H. Hajishirzi, T. Khot, A. Sabharwal, S. Singh, and Y. Choi. Prompt waywardness: The curious case of discretized interpretation of continuous prompts. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3631–3643, Seattle, United States, July 2022. Association for Computational Linguistics.
[12] T. Kojima, S.S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa. Large language models are zero-shot reasoners. arXiv preprint arXiv:2205.11916, 2022.
[13] B. Lester, R. Al-Rfou, and N. Constant. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics.
[14] Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), abs/2101.00190, 2021.
[15] J. Liu, D. Shen, Y. Zhang, B. Dolan, L. Carin, and W. Chen. What makes good in-context examples for GPT-3? In Proceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures, pages 100–114, Dublin, Ireland and Online, May 2022. Association for Computational Linguistics.
[16] Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 61–68, Dublin, Ireland, May 2022. Association for Computational Linguistics.
[17] Y. Lu, M. Bartolo, A. Moore, S. Riedel, and P. Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8086–8098, Dublin, Ireland, May 2022. Association for Computational Linguistics.
[18] S. Min, X. Lyu, A. Holtzman, M. Artetxe, M. Lewis, H. Hajishirzi, and L. Zettlemoyer. Rethinking the role of demonstrations: What makes in-context learning work? In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11048–11064, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics.
[19] S. Mishra, D. Khashabi, C. Baral, C. Yejin, and H. Hajishirzi. Reframing instructional prompts to GPTk’s language. pages 589–612, 01 2022.
[20] A. Prasad, P. Hase, X. Zhou, and M. Bansal. GrIPS: Gradient-free, edit-based instruction search for prompting large language models. ArXiv, abs/2203.07281, 2022.
[21] T. Shin, Y. Razeghi, R.L. Logan IV, E. Wallace, and S. Singh. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. pages 4222–4235, 01 2020.
[22] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi`ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample. LLaMA: Open and efficient foundation language models, 02 2023.
[23] A. Wang, Y. Pruksachatkun, N. Nangia, A. Singh, J. Michael, F. Hill, O. Levy, and S.R. Bowman. SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems. Curran Associates Inc., Red Hook, NY, USA, 2019.
[24] Y. Wang, S. Mishra, P. Alipoormolabashi, Y. Kordi, A. Mirzaei, A. Naik, A. Ashok, A.S. Dhanasekaran, A. Arunkumar, D. Stap, E. Pathak, G. Karamanolakis, H. Lai, I. Purohit, I. Mondal, J. Anderson, K. Kuznia, K. Doshi, K.K. Pal, M. Patel, M. Moradshahi, M. Parmar, M. Purohit, N. Varshney, P.R. Kaza, P. Verma, R.S. Puri, R. Karia, S. Doshi, S.K. Sampat, S. Mishra, A.S. Reddy, S. Patro, T. Dixit, and X. Shen. Super-Natural Instructions: Generalization via declarative instructions on 1600+ NLP tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5085–5109, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics.
[25] J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. Chi, Q. Le, and D. Zhou. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022.
[26] J. Wei, J. Wei, Y. Tay, D. Tran, D. Webson, Y. Lu, X. Chen, H. Liu, D. Huang, D. Zhou, and T. Ma. Larger language models do in-context learning differently, 2023.
[27] J. Yoo, K. Perlin, S.R. Kamalakara, and J.G.M Arau ́jo. Scalable training of language models using jax pjit and tpuv4. https://arxiv.org/pdf/2204.06514.pdf, 2022.
[28] W. Yuan, G. Neubig, and P. Liu. BARTScore: Evaluating generated text as text generation. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 27263–27277. Curran Associates, Inc., 2021.
[29] S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin, T. Mihaylov, M. Ott, S. Shleifer, K. Shuster, D. Simig, P. S. Koura, A. Sridhar, T. Wang, and L. Zettlemoyer. OPT: Open pre-trained transformer language models. arXiv:2205.01068, 2022.










































































































