
Oct 12, 2022
Vector AI Engineering blogs offer insights into applied machine learning and engineering work happening in the AI Engineering team. They are written by AI Engineering staff in collaboration with Vector Institute students, post-docs and faculty members, and affiliates. As well as Industry partners.
Vector contributors include: John Jewell, Shihao Ma, Deval Pandya
As high-resolution satellite imagery becomes increasingly available in both the public and private domains, several beneficial applications that leverage this data are enabled. Extraction of building footprints in satellite imagery is a core component of many downstream applications of satellite imagery such as humanitarian assistance and disaster response.
This work offers a comparative study of deep learning-based methods for building footprint extraction in satellite imagery.
What is semantic segmentation?
Semantic segmentation is a subclass of image segmentation where pixels are grouped together based on their class. It plays a critical role in a broad range of applications such as autonomous driving (e.g. self-driving cars or autonomous trains), geospatial analysis (e.g. building footprint extraction) and medical image segmentation (e.g. biomedical marker discovery). The goal of semantic segmentation is to label each pixel of an image with a class, effectively partitioning the pixels in the image into groups based on object type. Due to the high dimensional nature of both the input and the output space, semantic segmentation has traditionally been a very challenging task in computer vision [2]. Fortunately, recent supervised deep learning approaches have achieved robust semantic segmentation performance on a variety of challenging benchmarks [3]. These approaches use large datasets of images with corresponding pixel-wise labels to train neural networks by iteratively updating the parameters of the model to minimize a differentiable loss that characterizes the difference between predictions and labels. At inference, new samples are fed to the network and it produces a segmentation map with the same spatial resolution as the input image that encodes the label of each pixel.
Building Footprint Extraction
Inspired by the impressive performance of semantic segmentation models, significant effort has been made to transfer the success of deep learning-based semantic segmentation methods to building footprint extraction. Building footprint extraction is a special case of semantic segmentation that involves segmenting building footprints in satellite images.
Dataset
The SpaceNet Building Detection V2 dataset [1] is used to benchmark different approaches in this study. This dataset contains high resolution satellite imagery and corresponding labels that specify the location of building footprints. The dataset includes 302,701 Building Labels from across 10,593 multispectral satellite images of Las Vegas, Paris, Shanghai and Khartoum. The labels are binary and indicate whether each pixel is building or background, as can be seen in Figure 1.

Methods explored
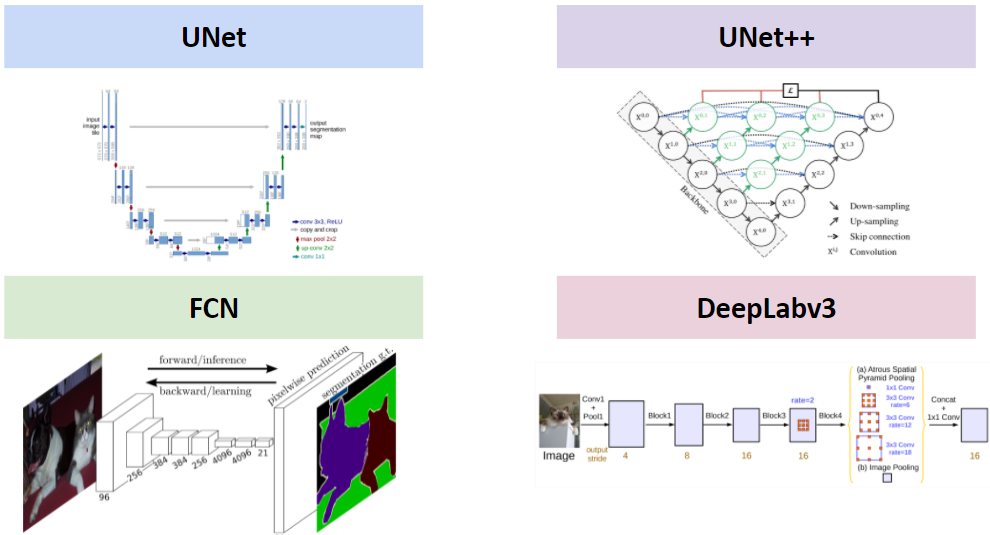
The four approaches to semantic segmentation that were explored include: U-Net [3], U-Net++ [7], Fully Convolutional Networks (FCN) [5] and DeepLabv3 [10]. These architectures are depicted in Figure 2. For both FCN and DeepLabv3, two variants of the architecture with different backbones (Resnet-50 and Resnet-100) are included. Thus, in total, six approaches are benchmarked on the task of building footprint extraction in aerial images.
U-Net: U-Net is an encoder-decoder architecture for semantic segmentation. The encoder consists of a contracting path to capture context and the decoder consists of an expanding path that enables precise localization [3]. Skip connections copy feature maps from the encoder to the decoder layers at the same level of the spatial resolution hierarchy. This enables the flow of high level information that may be lost in the low dimensional output of the encoder [3].
U-Net++: U-Net++ is an encoder-decoder architecture for semantic segmentation that builds on U-Net by linking the encoder and decoder through a series of nested, dense skip pathways. The re-designed skip pathways aim to reduce the semantic gap between the feature maps of the encoder and decoder sub-networks [7]. When compared with the U-Net architecture, U-Net++ not only has direct or skipped connections between down-sampling layers and up-sampling layers but also convolutional connections, which can pass more features into the up-sampling layers.
FCN: FCN maps arbitrary-sized input images to predicted semantic maps using solely convolutional layers [5]. In-network up-sampling layers are leveraged to make pixel-wise predictions by increasing the spatial resolution of the features generated by the backbone of the network to the height and width of the output. Once up-sampled, semantic information from low resolution feature maps is combined with appearance information from high resolution feature maps to produce precise segmentations. Both an FCN with a Resnet-50 backbone (FCN-50) and a Resnet-101 backbone (FCN-101) are benchmarked in the experiments section. The backbones are pretrained using the COCO train2017 semantic segmentation dataset [22] and fine-tuned for the building footprint extraction task.
DeepLabv3: DeepLabv3 is an encoder-decoder architecture for semantic segmentation that leverages dilated convolutional filters to increase the receptive field of the network and prevent excessive down-sampling [10]. A Spatial Pyramid Pooling module is used to capture context at multiple resolutions which is helpful in localizing objects of different sizes. Standard convolutional layers are factored into depth-wise separable convolutions followed by point-wise convolutions. This dramatically reduces the floating point operations per convolutional layer while maintaining network expressiveness. Both variations of DeepLabv3, with a Resnet-50 backbone (DLV3-50), and a Resnet-101 backbone (DLV3-101) are benchmarked in the experiments section. The backbones are pre-trained using the COCO train2017 semantic segmentation dataset [22] and finetuned for the building footprint extraction task.
Results
Intersection over Union, as depicted in Figure 3, is an evaluation metric used to measure the accuracy of an object detector on a particular dataset.

Examining this equation you can see that Intersection over Union is simply a ratio. In the numerator we compute the area of overlap between the predicted bounding box and the ground-truth bounding box. The denominator is the area of union, or more simply, the area encompassed by both the predicted bounding box and the ground-truth bounding box. Dividing the area of overlap by the area of union yields our final score — the Intersection over Union(IoU)
The IoU of each method on the test set is reported in Table 1. DLV3-101 achieves the best performance with an IoU of 0.7734 followed closely by DLV3-50, FCN-50 and FCN-101. U-Net and U-Net++ perform comparatively worse with an IoU of 0.5644 and 0.6554, respectively. The performance gap can be attributed to the fact that FCN-50, FCN-101, DLV3-50 and DLV3-100 benefit from pre-training whereas U-Net and UNet++ do not. This performance gap is also apparent in Figure 4 which shows the train and validation loss of each method across epochs. Methods that leverage pretraining are able to achieve better performance on both the train and validation set from the onset of training. The validation loss begins to plateau after only a few epochs which suggest that training is finished and should be early stopped to prevent overfitting. Alternatively, U-Net and U-Net++ have train and validation losses that consistently decrease over the course of training. This highlights the fact that models that leverage pretraining converge to the optimal set of parameters faster, in addition to offering better performance.
| Model | IoU |
| U-Net | 0.5664 |
| U-Net++ | 0.6554 |
| FCN-50 | 0.7455 |
| FCN-101 | 0.7472 |
| DLV3-50 | 0.7612 |
| DLV3-101 | 0.7734 |

Qualitative results are available in Figure 5, which shows an example input image, ground truth label and predicted semantic map for each method. The prediction quality of the methods parallels the quantitative results but performance is impressive across the board. The methods are able to generate precise semantic maps in scenes densely populated with building footprints. Additionally, predicted semantic maps in scenes that are sparsely populated with building footprints are robust to false positives, even in cases where roadways, parking lots or other structures are present. A preliminary analysis of the importance of model architecture conditioned on pretraining yields interesting results. The performance among methods that leverage pre training is similar, even across different architectures and backbones. Conversely, when considering the performance among methods that do not leverage pretraining, U-Net++ vastly outperforms U-Net. Although this warrants further experiments to validate, one hypothesis is that model architecture becomes less relevant as the amount of pretraining increases.

Conclusion
In this study, we trained and evaluated several state-of-the-art semantic segmentation models using the SpaceNet dataset, including U-Net, UNet++, FCN and DeepLabv3. Our results showed that DeepLabv3 with a Resnet-101 backbone is the most accurate approach to building footprint extraction among the models we explored. Models that leverage pretraining (i.e. FCN-50, FCN-101, DLV3-50 and DLV3-101) achieve higher accuracy and require minimal training compared to models without pretraining (i.e. U-Net and UNet++). This study implies that it is suitable to apply transfer learning for the task of building footprint extraction using satellite imagery.
Resources
[1] A remote sensing dataset and challenge series.
[2] Image Segmentation Using Deep Learning: A Survey
[3] U-net: Convolutional networks for biomedical image segmentation.
[5] Fully convolutional networks for semantic segmentation.
[7] Unet++: A nested u-net architecture for medical image segmentation
[10] Rethinking atrous convolution for semantic image segmentation.
[12] Deep residual learning for image recognition.
[15] Fully residual convolutional neural networks for aerial image segmentation.







































































































