
By Jonathan Woods
March 14, 2022
This article is a part of our Trustworthy AI series. As a part of this series, we will be releasing an article per week around
- Interpretability
- Fairness
- Governance
In this week’s article Vector’s Industry Innovation team breaks down ML interpretability challenges in order to help organizations think through their governance and offer general principles for ML model interpretability governance.
Model interpretability is a key element of machine learning governance. The ability to consistently predict a model’s result and understand how it came to that result is key to answering important questions, including:
- Can we trust the model we’re using?
- Do we understand what the model does?
- Can we explain how the model came to its conclusions?
Interpretability isn’t a new concern. Governance of traditional, ‘rules-based’ software models typically requires the ability to fully understand how they operate. However, machine learning (ML) presents new challenges that make interpretability significantly more complex, and render conventional techniques for achieving it no longer fit-for-purpose. Due to ML’s unique characteristics, the use of traditional interpretability approaches can even be counterproductive, inadvertently leading to adverse outcomes and degrading trust in learning systems more generally.
It isn’t hard to imagine contexts in which clear answers about how a model operates can be vital. Doctors and patients may demand a high degree of interpretability to support rationales for a model’s recommendations about medical interventions and treatment plans. Online media companies may want transparency where abuse, unfairness, or other undesirable content-related practices are apt to occur and be amplified. Investigators may need to know how an autonomous vehicle model came to settle on decisions that led to an accident.
At first glance, a solution may seem intuitive: simply make ML models as interpretable as possible by default. Unfortunately, it’s not so simple. In some cases, increasing interpretability requires a trade-off with model performance, and there’s no standard guideline as to when one should be favoured over the other. To get a sense of that problem, consider the following (paraphrased) hypothetical that was put forward by Vector Chief Scientific Advisor Geoffrey Hinton. Suppose a patient needs an operation and must choose between an ML surgeon that’s a black box but has a 90% cure rate and a human surgeon with an 80% cure rate. Which choice is better for the patient?[1] Should clinicians demand full model transparency so that they know exactly what the model does throughout the operation, even if it means reduced performance? Or should they be willing to forgo transparency in order to give the patient the best chance of a successful outcome?
This type of judgment call will need to be made for ML applications throughout industry and broader society. The challenge is that currently there’s no consensus on what the right answer is – or really even on how to approach the question.
Clearly, a future with widespread ML adoption will require widespread implicit trust. Ideally, ML will become as trusted a technology as electricity. Everyone knows electricity presents hazards, and yet no one worries that they’ll burn their house down if they turn on the lights. Knowledge and best practices in risk mitigation tailored to ML will be required for society to achieve that level of confidence with this new technology. Understanding the difficulties and determining the right level of interpretability for each use case in question – along with the right ways to achieve it – will be a crucial part of developing these. The alternative may be a long chapter in which ML is relegated to low-stakes tasks only, leaving the massive value it promises on the table.
Step one is understanding the challenge. In this paper, the Vector Institute’s Industry Innovation team breaks down interpretability challenges related to ML in order to help organizations think through its governance. Challenges related to industry, objectives, complexity, and technique limitations are separately addressed before the paper puts forward general principles for machine learning model interpretability governance. The insights in this paper were shaped by input from various Vector Institute industry sponsors.
Machine learning challenges: Traditional interpretability practices don’t measure up
Model risk governance frameworks typically include an interpretability component. However, the practices often used for conventional software are not reliable enough to effectively manage risk when applied to ML models. Consider some of the challenges of applying typical interpretability techniques to machine learning:
- Interpreting the model’s overall behaviour. A thorough knowledge and understanding of a conventional model’s structure, assumptions, and constraints may suffice to make confident determinations about how it operates. However, when it comes to machine learning, model outputs are based on conditional interactions between dependent and independent features, often making model operation too complex to articulate by simply referring to a set of rules. Many machine learning models have no explicit coefficients and no statistical significance tests for a given feature, making it exceptionally difficult to determine the weights assigned to a feature as it appears in various computations during model operation. This limits how thoroughly one can understand a model by simply knowing its design.
- Feature interpretability. Having a complete understanding of each feature – that is, each individual property or independent variable used as an input in a system – can contribute to developing a complete understanding of the model’s operation. However, automated feature engineering is gaining prevalence. For instance, generative models can create their own inputs. As this continue, it may become more of a challenge to completely understand features, and use that understanding to shed light on model operation.
- Solution transparency. Traditionally, designing a model’s technical details to be transparent can aid in determining how a model comes to its output. In machine learning, these details may include the number of layers in a neural network or the nodes and splits of a decision tree. Unfortunately, simply knowing these details doesn’t necessarily provide enough insight into how specific predictions are made.
- The ability to consistently reproduce a model’s results using the same inputs is one method for determining how a model works. However, for machine learning, model complexity, hardware variability, and compute cost can make reproducing a model’s results challenging and prohibitively expensive.
It’s clear that meeting interpretability needs for machine learning model governance will require new additional techniques.
Ambiguities and uncertainties related to ML interpretability
In the absence of standards, several challenges complicate the development and inclusion of meaningful interpretability practices as a part of governance. Awareness of each of these challenges is crucial for organizations attempting to determine their interpretability requirements and methods. The main challenges can be divided into four categories. They are:
- industry-specific challenges;
- goal and objective-related challenges;
- model complexity challenges; and
- technique-related challenges.
The following tables delineate concerns in each category, describing challenges, their implications, and their potential impacts on customers or end users.
Industry challenges
Different industries will have different requirements for explainability. An industry in which most applications are low-stakes – applications such as workforce scheduling – may not require stringent interpretability standards, as the risk of harm or unintended consequences is relatively low. With that said, interpretability standards are not only about reducing harm, but also about increasing trust in machine learning more generally, and the degree to which that must be done likely requires discussion and negotiation by organizations and their stakeholders on a case-by-case basis.
The table below describes some of the main industry-level challenges companies should recognize when considering how interpretability will fit into the governance of their machine learning model use.
Table 1: Industry challenges

Objectives & approach challenges
What the appropriate degree of model interpretability is may depend on what the model is being used for. There are often cases in which the predictive abilities of black box models far exceed those of humans, and in which deferring to the model’s output may result in higher-quality outcomes. Changing the model to increase transparency may reduce its performance. In these cases, careful consideration must be made to determine the right balance between two objectives: namely, transparency and quality of outcomes. There is a subjective exercise, and will depend on the values and norms of the organization, industry in which it operates, and society in general.
There are additional issues that may impact the approach to interpretability. One is the degree to which organizations feel comfortable relying on ‘explainable machine learning’ services, which are advertised as being able to provide full accounts of how black-box models operate. These should be approached with a healthy skepticism. The consequence of misplaced trust in such a service may be that a model use case in which interpretability should be prioritized isn’t due to overconfidence in an explainable machine learning service. A second issue is the potential for nefarious activities – including manipulation and malicious attacks – to impact model output. If the possibility is high or consequential, it may tip the balance toward greater prioritization of interpretability over performance.
The table below provides a description of each of these issues along with potential impacts.
Table 2: Objectives & approach challenges
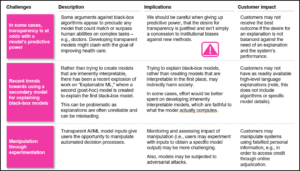
Model complexity challenges
Higher model performance often means greater model complexity, which often results in reduced interpretability. There may simply technical limitations to the level of interpretability one can expect if employing a particularly complex model.
The table below describes the challenges and impacts of model complexity.
Table 3: Model complexity challenges
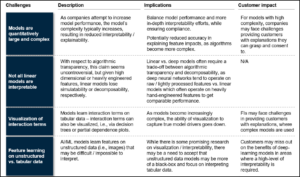
Technique limitations
Each technique used for interpretability has limitations. For instance, post-hoc interpretability ― interpreting the operation of a model after-the-fact through natural language explanations or visualizations ― can confer useful information, and may be tempting to perform as it doesn’t require changes to the model that may decrease performance. However, one must be cautious: humans can become convinced of plausible yet incomplete – or worse, entirely incorrect – explanations because they seem to fit an observed pattern. While existing techniques are certainly useful, they should not be mistaken for sure-fire methods that will guarantee interpretability
Table 4 describes various post-hoc interpretability techniques along with their risks and controls.
Table 5 describes some technique limitations and their implications.
Table 4. ML post-hoc interpretability techniques
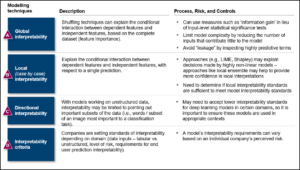
Table 5: Technique limitations

Principles: Approaching interpretability amid ambiguity
Considering these challenges, how can an organization approach interpretability and include it as a part of a suitable governance framework? Below are general principles about approaching interpretability when managing model risk.
- Define model governance
What governance means must be defined by each organization, with consideration given to the organization’s size, corporate values, industry norms, and stakeholders’ interests. Controls should adhere to principles of fairness and social acceptability, and should involve every aspect of the model’s lifecycle – from ideation and development to deployment and monitoring. Articulating these principles and concepts is a crucial first step.
- Ensure interpretability is part of governance
Interpretability needs to factor into the assessment of machine learning model risk and fit within the company’s approach to governing model risk more broadly. The level of interpretability desired for a model should be defined early on its design to minimize performance trade-offs and potential adverse impacts.
- Strive for thorough model knowledge
While challenges exist to gaining thorough knowledge of how a model operates or features generated by machine learning models themselves, the goal should always be to maximize understanding. This includes understanding of the data sources or inputs being used, the model structure, assumptions involved in its design, and existing constraints. This knowledge is essential to demonstrating an AI/ML model’s conceptual soundness and suitability for a use case.
- When interpretability is definitely required, opt for inherently interpretable models
When a use case and its context require that a model’s operation be transparent, it may be more prudent to design inherently interpretable models than to apply approaches and techniques that attempt to achieve interpretability post-hocWhile a number of approaches and techniques can enhance interpretability even in ML models, it may be more effective to put effort towards designing inherently interpretable models in high-stakes or high-risk scenarios.
- Avoid a one-size-fits-all approach
Organizations should consider using different techniques according to the ML model’s risk in each specific application. This means avoiding prescriptive or standardized approaches when it comes to setting model interpretability requirements, as these may result in the selection of sub-optimal models and technologies.
- Commit to ongoing monitoring and continuous learning
Learning how to assess risk accurately, determine the optimal accuracy versus performance trade-off for each use case and model, and decide on the best approaches for an organization and industry require time, ongoing monitoring of a model’s outcomes, and continuous learning. Organizations should continue to fine-tune their understanding of the techniques, risks, and outcomes for each model and application, so as to gain a more fulsome understanding of interpretability’s role in governance and of how to tailor their approach in various contexts.
Summing up
Machine learning presents a tremendous opportunity to improve productivity, innovation, and customer service across domains. However, the technology carries risks and there’s no standard playbook for mitigating them. Enjoying ML’s upside means finding a way to responsibly move forward with the technology despite this uncertainty.
Trust – by employees, customers, and the broader public – will be key to enjoying the full benefits that machine learning has to offer. To achieve that trust, organizations need to determine and adopt appropriate ML model governance practices, including those related to interpretability. Doing so begins with understanding the unique challenges that ML models present to interpretability efforts as well as the steps for determining the degree of model transparency required, the methods that will ensure it is provided, and the considerations involved when determining which trade-offs are appropriate in each use case.
[1] https://twitter.com/geoffreyhinton/status/1230592238490615816?lang=en
















