State of Evaluation Study: Vector Institute Unlocks New Transparency in Benchmarking Global AI Models
April 10, 2025
2025
AI Engineering
Research
Research 2025
April 10, 2025
Vector Institute’s first State of Evaluation study, developed by Vector’s AI Engineering team, shines new light on the evaluation and benchmarking of AI models. In a first for this kind of research, Vector is sharing both the results of the study, as well as the underlying code in open source to promote transparency and accountability.
AI companies are developing and commercializing new and more powerful large language models (LLMs) at an unprecedented pace. Each new model promises greater capabilities from more human-like text generation to advanced problem-solving and decision-making. Developing widely used and trusted benchmarks advances AI safety; it helps researchers, developers, and users understand how these models perform in terms of their accuracy, reliability, and fairness, enabling their responsible deployment.
Vector’s AI Engineering team assessed 11 leading AI models from around the world, examining both open- and closed-source models including the January 2025 release of DeepSeek-R1. Each agent was tested against 16 benchmarks including MMLU-Pro, MMMU, and OS-World, which were developed by Vector Institute Faculty Members and Canada CIFAR AI Chairs Wenhu Chen and Victor Zhong. These benchmarks are now used widely in the AI safety community.
The work also builds on Vector’s leading role in developing Inspect Evals — an open-source AI safety testing platform created in collaboration with the UK AI Security Institute to standardize global safety evaluations and facilitate collaboration among researchers and developers.
The open-source results, available in an interactive leaderboard below, offer valuable insights that can help researchers and organizations understand the quickly-evolving capabilities of these models.

“Robust benchmarks and accessible evaluations of models enable researchers, organizations, and policymakers to better understand the strengths, weaknesses, and real-world impact of these rapidly evolving, highly capable AI models and systems.”
Deval Pandya
Vice President of AI Engineering at Vector Institute
The team selected a range of leading open- and closed-source frontier models. Vector included both commercial and publicly available models to provide a holistic view of the current AI landscape and to better understand the capabilities, limitations, and societal impacts of frontier models in widespread use.
| Open-source models | Closed-source models (all U.S.) |
|---|---|
| Qwen2.5-72B-Instruct (Alibaba/China) | GPT-4o (Open AI) |
| Llama-3.1-70B-Instruct (Meta/U.S.) | O1 (Open AI) |
| Command R+ (Cohere/Canada) | GPT4o-mini (Open AI) |
| Mistral-Large-Instruct-2407 (Mistral/France) | Gemini-1.5-Pro (Google) |
| DeepSeek-R1 (DeepSeek/China) | Gemini-1.5-Flash (Google) |
| Claude-3.5-Sonnet (Anthropic) |
Vector Institute credits their research ecosystem partner CentML for facilitating access to DeepSeek R1 for this evaluation.
The tests covered a range of questions and scenarios with increasing complexity, using two types of benchmarks. Single-turn benchmarks are short, question-and-answer style tasks focused on reasoning, knowledge recall, or multimodal understanding in a static context. A biological knowledge question posed to the model could be similar to: “Which of the following, (a) Commensalism, (b) Succession, (c) Mutualism, or (d) Parasitism, is NOT a form of interspecies interaction?”. Agentic benchmarks require models to make sequential decisions, navigate environments, and potentially use tools (e.g., browsers, terminals) to solve multi-step challenges. They simulate real-world scenarios, executing high-level tasks like: “Book a restaurant reservation for two at an Italian restaurant in downtown Toronto this Saturday at 7 PM”.
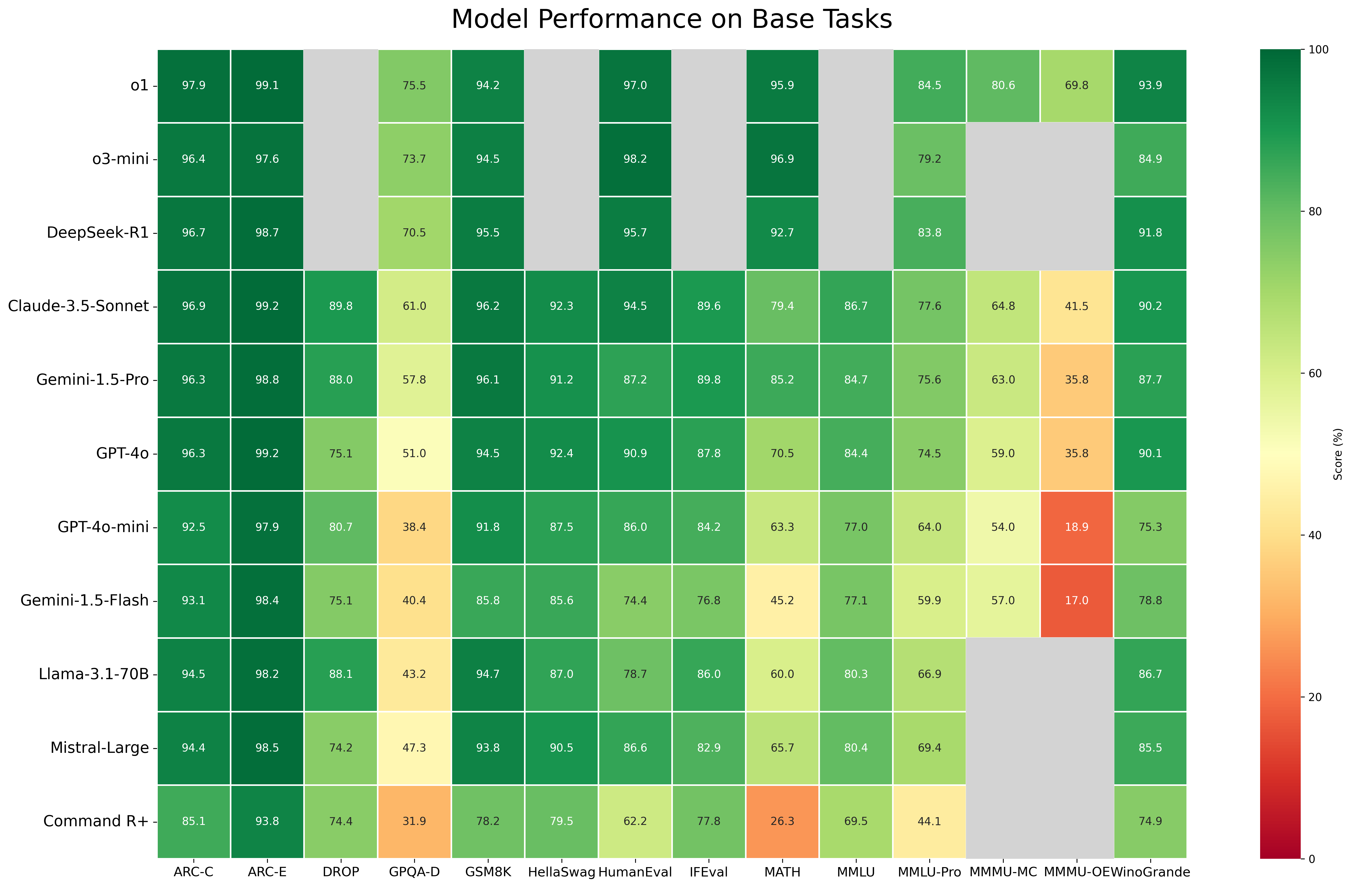
Fig 1. An at-a-glance heat map reveals relative performance against base tasks.
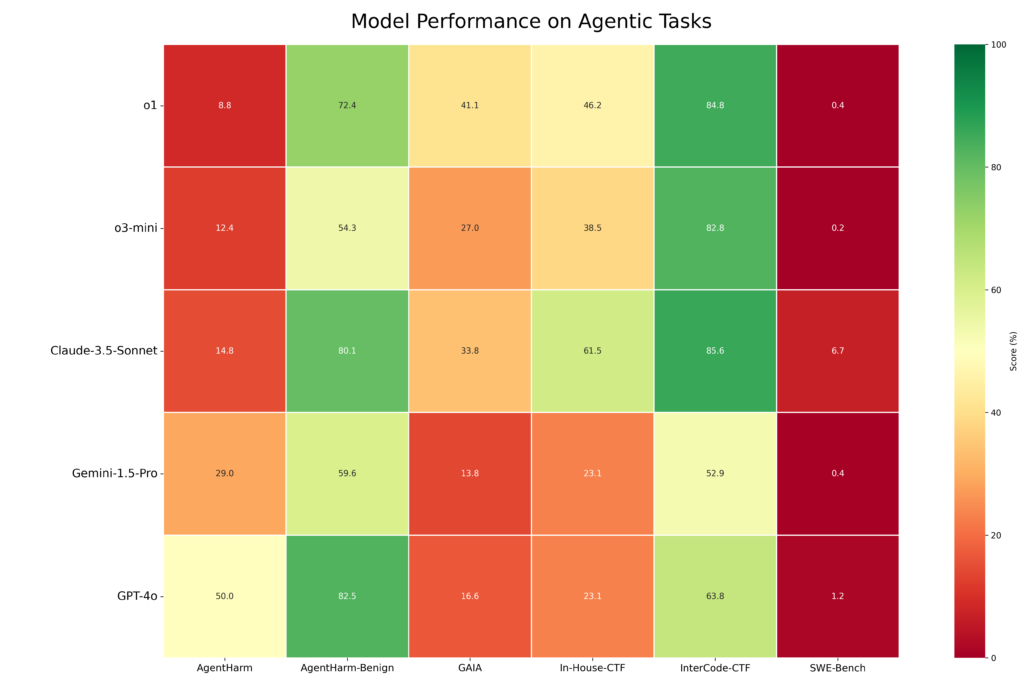
Fig 2. Vector’s evaluation of performance on agentic tasks reveals greater variance.
This study is the first time that an independent organization has open-sourced a set of results from this suite of benchmarks. Vector also worked with Google DeepMind to open-source and independently validate their “Dangerous Capabilities” benchmarks, elevating the breadth and transparency of the findings.
“This kind of open, reproducible, and independent assessment helps to separate ‘noise’ from ‘signal’ around the promised capabilities of these models, particularly for the closed models where independent performance information is hard to obtain,” notes John Willes, Vector’s AI Infrastructure and Research Engineering Manager, who led the project. “Sharing the study’s data, benchmarks, and code via open-source fosters transparency, reproducibility, and collaboration throughout the AI community.


“Now researchers, regulators, and end-users can independently verify results, compare model performance, and build upon this to implement their own evaluation benchmarks and execute their own evaluations.”
John Willes
AI Infrastructure and Research Engineering Manager at Vector Institute
Complete results are available in the leaderboard. Three highlights reveal leaders and laggards in model performance.
Overall, closed-source models tended to outperform open-source models, especially in complex tasks. However, DeepSeek’s R1 performance shows that open-source models can achieve competitive performance across most benchmarks and domains. For the most challenging knowledge and reasoning tasks, especially those with complex question formats, the top closed-source models maintained a significant performance advantage over their open-source counterparts. Organizations should consider factors beyond raw performance when choosing an AI model, weighing the benefits of open-source (transparency, community-driven improvement) against the potentially higher performance of certain closed-source models. The choice involves strategic considerations around long-term innovation and risk management.
Agentic benchmarks, designed to assess real-world problem-solving abilities, proved challenging for all 11 models that the Vector team evaluated. The agentic evaluation used the Inspect ReAct agent and employed benchmarks spanning several domains:
o1 and Claude 3.5 Sonnet demonstrated the strongest capabilities on agentic tasks, especially structured tasks with explicit objectives, outperforming GPT-4o and Gemini 1.5 Pro. However, all models struggled with tasks requiring greater open-ended reasoning and planning capability. Performance on software engineering tasks evaluated using SWE-Bench-Verified was poor across all models without domain-specific agent scaffolding. o1 and Claude 3.5 Sonnet also exhibited better safety profiles due to higher refusal rates for harmful requests, compared to GPT-4o and Gemini 1.5 Pro.
For developers, the key takeaway is that complex, specialized tasks—such as those in software engineering—will require advanced scaffolding beyond generalist agents with tool-use capabilities. Product designers will need to build additional structure around the models to deliver high performance in demanding, real-world scenarios without significant advancements in the underlying models.
Real-world applications need AI systems that can process and reason with diverse information types—images, text, and audio—similar to human perception and interaction with the world. For example, in health care, multimodal AI can analyze medical images alongside patient records to assist in diagnosis and treatment planning. This ability to understand and integrate different types of information is fundamental to unlocking AI’s potential in numerous real-world scenarios.
The Multimodal Massive Multitask Understanding (MMMU) benchmark, developed by Vector Faculty Member and Canada CIFAR AI Chair Wenhu Chen, evaluates a model’s ability to employ reasoning for problems requiring both image and text interpretation across multiple-choice and open-ended question formats. The questions are further stratified by topic difficulty (easy, medium, hard) and domain, including math, finance, music, and history.
In the evaluation, o1 exhibited a superior multimodal understanding across various question formats and difficulty levels, as did Claude 3.5 Sonnet, but to a lesser extent. Most models experienced a significant performance drop when tasked with more challenging open-ended multimodal queries. This trend was consistent across all difficulty levels. o1 exhibited the most resilient profile, in that the drop was much less severe. Claude-3.5-Sonnet maintained relatively stable performance, but only at medium difficulty. Performance also generally declined with increasing question difficulty for all models.
These results indicate that while multimodal AI is advancing, open-ended reasoning and complex multimodal tasks remain significant challenges, highlighting areas for future research and development.
The rapid advancement of AI models highlights the need for evaluation frameworks capable of evolving alongside technological progress. Vector Institute’s research community and AI Engineering team continue to push the boundaries of the science of benchmarks and evaluation.
Vector Institute Faculty Members who are leading frontier work in benchmark development and AI safety shared their perspectives on the future of model evaluation.
Vector Faculty Member
Canada CIFAR AI Chair

Chen developed MMMU and MMLU-Pro, the two primary baselines now used by major model developers including Anthropic, OpenAI, and DeepSeek. He highlights the need for benchmarks that capture expert-level annotation from diverse fields to ensure accuracy, relevance, and practical utility. “The models are getting pretty close to human expert levels already. To annotate these questions, you really need physicists, mathematicians, Nobel prize-winners,” he says. “We still need a lot of effort from the other disciplines like medicine, law, or finance to provide very good datasets; models are simply not as advanced on these topics as they are on math and coding. The datasets need to be way more diverse and suited for general people instead of just for computer scientists.”
Vector Faculty Member
Canada CIFAR AI Chair

Rudzicz leads frontier research in natural language processing, speech, and safety, and is the co-author of “Towards international standards for evaluating machine learning.” He highlights the importance of aligning technical evaluations with practical, real-world impact. “Sometimes we computer science people need to understand the real-world metrics that relate to how the tools will be actually used,” he says. “On the other hand, sometimes the computer science community has a set of mathematical representations for concepts that are not widely known outside this community. We need to do a good job of communicating in that direction also.”
Vector Faculty Member
Canada CIFAR AI Chair

Additionally, evaluations must become living, dynamic processes rather than static snapshots. In addition to his research focus on building and training generalist language agents, Zhong developed OS World, the primary benchmark used by Anthropic, OpenAI, and others to report on computer use agents. Zhong argues for continuous and evolving evaluation methodologies. “We need to fundamentally rethink what it means to evaluate machine-learning systems,” he says. “As models evolve, evaluations can get outdated quickly. To keep pace, we’re going to see dynamic evaluations, which take resources and effort to maintain. We’ll also need to rethink the incentives around research – and research communities – to align with this notion of evaluation.”
Vector Institute Bronze sponsor Cohere aims to reshape the LLM landscape by addressing gaps in multilingual and multicultural performance.
The challenge: Traditional evaluation benchmarks are predominantly in English and tend to reflect Western-centric viewpoints.
The impact: Relying on translated English datasets risks missing out on regional and cultural nuances, leading to biased assessments. Applicability is especially limited for languages and cultures which are under-represented in datasets, often known as “low resource” languages.
The work: Led by the company’s research lab Cohere for AI, Aya is a global, open-science initiative that is creating new models and datasets to expand the number of languages covered by AI. Instead of focusing solely on translation and basic language tasks, the Aya benchmark project assesses deeper linguistic abilities, reasoning, and ethical considerations across languages.
“Our goal is to bridge linguistic gaps so that LLMs understand and respond appropriately to cultural nuances, rather than just translating words,” explains Cohere for AI leader Sara Hooker. “Through global collaboration, Aya is advancing more inclusive benchmarks and shaping a more equitable AI ecosystem that serves diverse communities fairly.”
As a leader in developing novel benchmarks and independent evaluation, Vector aims to set global standards for AI, so that AI can be trusted, safe, and aligned with human values wherever it is used. Vector aims to empower all parties to develop AI responsibly, and to bridge research to real-world application.


“Independent, public evaluations are a public good that can drive improvements in AI safety and trust.”
David Duvenaud, Vector Faculty Member and Canada CIFAR AI Chair


