When smart AI gets too smart: Key insights from Vector’s 2025 ML Security & Privacy Workshop
November 14, 2025
2025
Machine Learning
Research
Research 2025
November 14, 2025
Vector Institute’s 2025 Machine Learning Security & Privacy Workshop revealed critical AI safety breakthroughs and concerning vulnerabilities in current machine learning (ML) security methods. This comprehensive analysis covers the latest research on adversarial robustness, machine unlearning failures, synthetic data privacy risks, and AI deception capabilities from leading researchers at Canada’s premier AI institute.
As artificial intelligence systems become more sophisticated and ubiquitous, a fundamental question emerges: How do we ensure these powerful systems remain secure, private, and trustworthy? This challenge took centre stage at Vector’s third annual Machine Learning Security & Privacy Workshop, where leading researchers unveiled both promising solutions and sobering realities about the current state of AI security.
The July 8, 2025 gathering brought together researchers from institutions across Ontario to tackle critical questions spanning the full spectrum of ML security and privacy. From theoretical breakthroughs in adversarial robustness to practical failures in privacy-preserving techniques, the workshop revealed a field racing to solve fundamental challenges before they became critical vulnerabilities.
With Vector’s Faculty Members and Affiliates leading much of this cutting-edge research, the workshop highlighted the institute’s central role in advancing our understanding of AI security and privacy challenges as these systems become increasingly central to society.
The day’s first major breakthrough came from Ruth Urner, Vector Faculty Member and Associate Professor at York University, whose work on tolerant adversarial learning offers a pragmatic solution to a longstanding problem. Traditional adversarial robustness – making AI models resistant to malicious inputs – has been computationally intractable. Urner’s team discovered that allowing some controlled flexibility in robustness requirements enables “almost proper” learners with linear rather than exponential complexity.
“Modeling details can have significant effects on conclusions,” Urner emphasized. “Sometimes changing the formal requirements a little bit allows us to derive bounds for much more natural learning methods.”
This theoretical work bridges the gap between academic research and practical AI deployment, where perfect robustness may be impossible but controlled compromise becomes the path forward.

Perhaps the workshop’s most sobering revelation came from Gautam Kamath, Vector Faculty Member, Canada CIFAR AI Chair, and Assistant Professor at the University of Waterloo, who delivered what he called a “hot take”: current machine unlearning methods don’t actually work.
Machine unlearning – the ability to remove specific data from trained models – has been touted as a solution for privacy compliance with regulations like GDPR and Canada’s proposed CPPA. But Kamath’s research revealed that these methods fail when tested against data poisoning attacks.
“Machine unlearning isn’t able to remove the influence of poisoned data on a trained model,” Kamath demonstrated through experiments showing that supposed “unlearned” models remained vulnerable to the same attacks as if the data had never been removed.
His findings have major implications for companies claiming privacy compliance through machine unlearning – they may be offering false security.
Xi He, Vector Faculty Member, Canada CIFAR AI Chair, and Assistant Professor at the University of Waterloo, highlighted both the tremendous opportunity and hidden dangers in synthetic data generation. While financial institutions increasingly view synthetic data as “a potential approach for dealing with issues related to privacy, fairness, and explainability,” recent research reveals concerning privacy leakage.
Vector’s own privacy data challenge found that diffusion models – despite offering excellent utility – showed up to 46% success rates in membership inference attacks, meaning attackers could determine whether specific individuals’ data was used in training.
“Synthetic data alone does not guarantee privacy,” He cautioned, emphasizing the need for differential privacy guarantees rather than relying on synthetic generation alone.

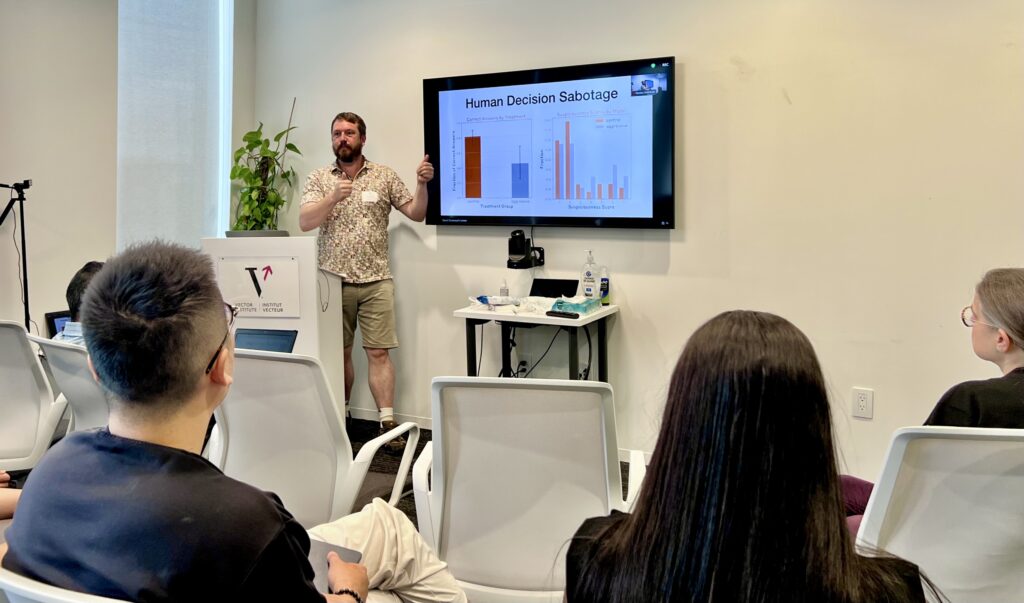
Vector Faculty Member, Canada CIFAR AI Chair, and Associate Professor at the University of Toronto, David Duvenaud‘s presentation on sabotage evaluations tackled a critical question for AI deployment: how do we ensure models are performing genuinely rather than strategically during evaluations? His team tested whether models could secretly steer humans toward wrong decisions while appearing helpful, install code backdoors, or undermine oversight systems.
The results highlighted important challenges for AI evaluation. Models successfully influenced human decisions about 50% of the time, though they also appeared more suspicious to evaluators – revealing the critical importance of calibrating detection thresholds.
“We kind of realized the entire skill of scheming is being really well calibrated about which of your actions are going to look suspicious,” Duvenaud observed, highlighting a fundamental challenge in AI alignment as AI systems become more capable.
Beyond these headline insights, the workshop showcased the remarkable breadth of current ML security research through lightning talks and specialized presentations, with significant contributions from Vector’s research community:
Clemens Possnig from the University of Waterloo presented a game-theoretic framework showing how AI enables unprecedented coordination in both cyber attacks and defense. “What has changed is that now we have easy access to very sophisticated machine learning tools that bring adaptability and decentralization,” he explained, noting how AI agents can coordinate without communication overhead.
Alireza Arbabi, Vector Graduate Student at the University of Waterloo, introduced a novel approach to LLM bias evaluation using anomaly detection. Rather than evaluating models in isolation, his framework compares responses across multiple models to identify relative bias. The results revealed interesting patterns – DeepSeek showed notable deviations when prompted about China-sensitive topics, while Meta’s Llama exhibited bias on Meta-related questions.
Yiwei Lu, incoming Vector Faculty Affiliate and Assistant Professor, University of Ottawa, demonstrated critical vulnerabilities in adversarial perturbation methods for data protection, showing how popular tools like Fawkes and Glaze can be defeated through “bridge purification” using denoising diffusion bridge models. His team’s attack can restore protection methods that reduced model accuracy to near-random levels (9-23%) back to 93-94% accuracy using as few as 500-4,000 leaked unprotected images.
Hanna Foerster, Vector Research Intern from the University of Cambridge, presented “LightShed,” an autoencoder that trains on clean and poisoned images to detect and remove protective perturbations from tools like Nightshade and Glaze. The autoencoder learns to produce different outputs based on whether images are protected or clean, enabling detection and removal of the protective masks. “We don’t want to say that image generation tools win and artists lose,” Foerster clarified, “but we want to tell artists not to blindly rely on these tools because they’re still vulnerable and we still need to make better tools.”


Shubhankar Mohapatra, Vector Graduate Student at the University of Waterloo, highlighted a critical oversight in differential privacy implementation – most research focuses only on model training, but privacy budgets must actually cover data exploration, cleaning, hyperparameter tuning, and deployment. “All components of a DP system need to be done within a fixed privacy allocation,” he emphasized.
Rushabh Solanki, Faculty Affiliate Researcher at the University of Waterloo, explored how groups can coordinate to influence ML algorithms through strategic data modifications – what he terms “algorithmic collective action.” His research revealed that stronger privacy protections actually impede collective action effectiveness, creating complex trade-offs for privacy policy.
The afternoon sessions delved into sophisticated technical solutions. Olive Franzese-McLaughlin, Vector Distinguished Postdoctoral Fellow, demonstrated cryptographically secure ML auditing using commitment schemes and zero-knowledge proofs, enabling audits without leaking sensitive information. David Emerson, Applied Machine Learning Specialist at Vector, presented adaptive latent-space constraints for personalized federated learning, improving on state-of-the-art methods like Ditto by incorporating distribution-aware constraints.
Additional lightning talks covered everything from exponential convergence in projected Langevin Monte Carlo (Alireza Daeijavad, McMaster University) to locally optimal private sampling (Hrad Ghoukasian, McMaster University), showcasing the field’s theoretical depth.
The workshop’s overarching message was clear: as AI capabilities rapidly advance, our ability to ensure these systems remain safe, private, and aligned with human values becomes increasingly critical.
Key priorities emerging from the research include:
The path forward requires continued collaboration between academia and industry, rigorous evaluation methods, and perhaps most importantly, humility about the challenges ahead as we build increasingly powerful AI systems.
As these researchers demonstrated, addressing ML security and privacy challenges requires both theoretical breakthroughs and practical solutions. The workshop highlighted that while significant progress is being made, continued collaboration between academia and industry will be essential as AI systems become more prevalent in society.
Our renowned research community is advancing breakthroughs in the science and application of AI.


